
This Project Pythia Cookbook covers working with large-scale scientific data using OpenViSUS.
Motivation¶
OpenViSUS enables interactive analysis and visualization of petabyte-scale scientific datasets on any device, from supercomputers to personal laptops. This cookbook will help you learn how to store, query, and visualize big data efficiently using OpenViSUS tools and formats.
Hierarchical Z-Order Data Storage¶
The NSDF-OpenVISUS framework leverages hierarchical Z-order curve for efficient data storage and access. This method organizes data to preserve spatial locality, enabling fast multi-resolution queries and scalable visualization.
Below is an illustration of hierarchical Z-order refinement:
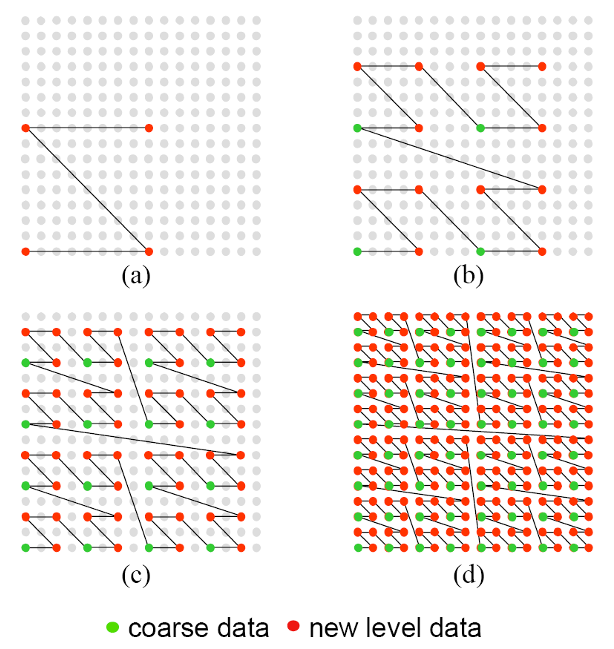
Panels:
(a) Initial coarse data points (green) and new level data (red).
(b), (c) Progressive subdivision, adding new data points in Z-order.
(d) Fully refined grid, showing efficient hierarchical access.
Note: This cookbook is part of the larger OSDF Cookbook, which can be found at https://
Authors¶
Aashish Panta, Valerio Pascucci, Amy Gooch, Giorgio Scorzelli
Contributors¶

Structure¶
This cookbook is organized into sections, which you can select from the sidebar on the left (see image above). Each section covers a different topic or dataset relevant to NSDF-OpenVISUS:
Preamble¶
Information on citing this NSDF-OpenVISUS Cookbook.
Introduction to NSDF-OpenVISUS¶
Overview of the NSDF-OpenVISUS framework, its motivation, and its role in scientific data visualization.
NASA DYAMOND Datasets (C1440–LLC2160)¶
Workflows for visualizing and analyzing NASA DYAMOND atmospheric and ocean datasets.
ECCO LLC4320 Datasets¶
Visualization and analysis of the ECCO LLC4320 ocean dataset, including data access, processing, and interactive exploration.
Running the Notebooks¶
You can either run the notebook using Project Pythia Binder or on your local machine.
Running on Binder¶
The simplest way to interact with a Jupyter Notebook is through Binder, which enables the execution of a Jupyter Book in the cloud. To launch a Pythia Cookbooks chapter via Binder, click the rocket ship icon at the top right corner of the book chapter and select “launch Binder.” After a moment, you should be presented with a notebook that you can interact with. You’ll be able to execute and even change the example programs. Code cells have no output at first, until you execute them by pressing Shift+Enter. See Getting Started with Jupyter for more details.
Note: Not all Cookbook chapters are executable. If you do not see the rocket ship icon, you are not viewing an executable book chapter.
Running on Your Own Machine¶
If you are interested in running this material locally on your computer, follow this workflow:
Clone the
https://github.com/ProjectPythia/nsdf-openvisus-cookbookrepository:git clone https://github.com/ProjectPythia/nsdf-openvisus-cookbookMove into the
OpenVisusdirectory:cd nsdf-openvisus-cookbookCreate and activate your conda environment from the
environment.ymlfile:conda env create -f environment.yml conda activate nsdf-cookbookMove into the
Samples/jupyterdirectory and start up JupyterLab:cd notebooks jupyter lab
References¶
Please consult these papers for technical details and use cases:
Web-based Visualization and Analytics of Petascale data: Equity as a Tide that Lifts All Boats
Interactive Visualization of Terascale Data in the Browser: Fact or Fiction?
Please reach out to Aashish Panta, Giorgio Scorzelli or Valerio Pascucci for any concerns about the notebook. Thank you!
Aashish Panta (aashishpanta0@gmail
.com) Giorgio Scorzelli (scrgiorgio@gmail
.com) Valerio Pascucci (pascucci
.valerio@gmail .com)