Section 1: Data access through PelicanFS and OSDF¶
Overview¶
This notebook provides an example of a scientific use-case of the PelicanFS framework by accessing data to be analyzed through federated OSDF caches. We use this data to analyze spectral changes of water tracks in a small area of interest in the Arctic. In this analysis we calculate NDVI index which we use to infer the greening and browning trends of the water tracks in the summer months as permafrost thaws.
We build a dataset from a catalog of open-access Sentinel-2 data from the Amazon Web Service (AWS). Normally, we would access this open data from AWS each time we need to run or re-run our analysis, and each time we would be making requests to the AWS servers. Given the vast spatial, temporal and spectral scale of the satellite data we use for our analysis, retrieving data can be time and resource costly depending on the infrastructure or network context from which we are performing our computation. With PelicanFS, we can reduce data acquisition times by performing our catalog search on OSDF federated caches. Additionally, when possible PelicanFS caches data that was previously unavailable in the OSDF cache so that next time we would be able to retrieve it from the cache. Ultimately, we expect that accessing data through PelicanFS will improve the overall time complexity of our analysis workflows.
Prerequisites¶
To better understand this notebook, please familiarize yourself with the following concepts:
| Concepts | Importance | Notes |
|---|---|---|
| Intro to OSDF | Recommended | Overview of OSDF |
| Overview of FSSpec | Necessary | To better understand the FSSpec library |
| Overview of Python xarrays | Necessary | An introduction to data manipulation using Xarray DataArrays and Datasets |
| Working with STAC catalogs | Necessary | An overview of SpatioTemporal Asset Catalog (STAC) catalogs for spatial data |
| Spatial STAC catalogs as xarray data structures; Working with STAC catalogs in Python | Necessary | Efficient computation of spatial raster data as STAC catalogs and xarray data structure in Python |
Time to learn: 30-45 minutes
Imports¶
from pelicanfs.core import PelicanFileSystem, PelicanMap,OSDFFileSystem
import matplotlib.pyplot as plt
import pandas as pd
import xarray as xr
import numpy as np
import urllib
import geopandas as gpd
import pystac_client
import stackstac
import rasterio
import shapelyBuild a STAC catalog of Sentinel-2 data from AWS¶
Here, we begin by building a catalog of Sentinel-2 data that we will access from AWS. The data will be in form of When we query our catalog, we obtain SPEC metadata objects which we will process further through the PySTAC library. As we see below, our catalog search returned 104 items, where item is a Sentinel-2 scene and take [cite, provide more info for S2 scenes, takes?] matching our AOI for June-October 2020.
# build a geometry of AOI from these coordinate bounds
aoiBounds = (134.66615966473387, 66.82737559988661, 134.72162967387277, 66.85380494758718)
aoiGeom = shapely.geometry.box(*aoiBounds)
lon, lat = 134.70071475239416, 66.84143426792251
startDate = '2020-06'
endDate = '2020-08'
# cloudCovMaxPct = 5
catalogURL = 'https://earth-search.aws.element84.com/v1'
search = pystac_client.Client.open(catalogURL).search(collections=['sentinel-2-l2a'],
# bbox=aoiGeom.bounds,
datetime=f'{startDate}/{endDate}',
intersects=dict(type="Point", coordinates=(lon, lat)),
# query={'eo:cloud_cover': {'lt': cloudCovMaxPct}}
)
# Get all matching items
items = list(search.items())
print(f'Found {len(items)} matching items.')Found 104 matching items.
Pointing STAC catalog to OSDF caches¶
Now is the time to utilize the capabilities of Pelican File System (PelicanFS) and OSDF caches. Remember that our STAC catalog contains metadata of our data. As mentioned above, each of the 104 items in our catalog is a Sentinel-2 scene for a particular timestamp matching our AOI. We can look up one of the items from the catalog to see its metadata.
print(items[0].properties){'created': '2023-09-11T15:41:31.053Z', 'platform': 'sentinel-2a', 'constellation': 'sentinel-2', 'instruments': ['msi'], 'eo:cloud_cover': 99.918234, 'mgrs:utm_zone': 53, 'mgrs:latitude_band': 'W', 'mgrs:grid_square': 'MQ', 'grid:code': 'MGRS-53WMQ', 'view:sun_azimuth': 172.641943803281, 'view:sun_elevation': 31.2265921212202, 's2:degraded_msi_data_percentage': 0.054, 's2:nodata_pixel_percentage': 87.71764, 's2:saturated_defective_pixel_percentage': 0, 's2:dark_features_percentage': 0.005051, 's2:cloud_shadow_percentage': 0.076015, 's2:vegetation_percentage': 0, 's2:not_vegetated_percentage': 0.000513, 's2:water_percentage': 0.000189, 's2:unclassified_percentage': 0, 's2:medium_proba_clouds_percentage': 11.694589, 's2:high_proba_clouds_percentage': 88.215214, 's2:thin_cirrus_percentage': 0.008428, 's2:snow_ice_percentage': 0, 's2:product_type': 'S2MSI2A', 's2:processing_baseline': '05.00', 's2:product_uri': 'S2A_MSIL2A_20200831T023551_N0500_R089_T53WMQ_20230318T225127.SAFE', 's2:generation_time': '2023-03-18T22:51:27.000000Z', 's2:datatake_id': 'GS2A_20200831T023551_027113_N05.00', 's2:datatake_type': 'INS-NOBS', 's2:datastrip_id': 'S2A_OPER_MSI_L2A_DS_S2RP_20230318T225127_S20200831T023553_N05.00', 's2:granule_id': 'S2A_OPER_MSI_L2A_TL_S2RP_20230318T225127_A027113_T53WMQ_N05.00', 's2:reflectance_conversion_factor': 0.980196377542162, 'datetime': '2020-08-31T02:39:02.945000Z', 's2:sequence': '1', 'earthsearch:s3_path': 's3://sentinel-cogs/sentinel-s2-l2a-cogs/53/W/MQ/2020/8/S2A_53WMQ_20200831_1_L2A', 'earthsearch:payload_id': 'roda-sentinel2/workflow-sentinel2-to-stac/0ec51ea6bb5ad08ed2ea1b04baa16351', 'earthsearch:boa_offset_applied': True, 'processing:software': {'sentinel2-to-stac': '0.1.1'}, 'updated': '2023-09-11T15:41:31.053Z', 'proj:code': 'EPSG:32653'}
We can peek further to see where the “assets” of this particular item is store by looking for its URL. As expected the URL points to a AWS bucket somewhere. This checks out, because out STAC catalog is build from Sentinel-2 data store in AWS.
items[0].assets['nir'].href'https://sentinel-cogs.s3.us-west-2.amazonaws.com/sentinel-s2-l2a-cogs/53/W/MQ/2020/8/S2A_53WMQ_20200831_1_L2A/B08.tif'Remember we are trying to access our data through PelicanFS, which will hopefully point us to an OSDF cache instead of AWS. If PelicanFS were able to do that, then the URL above would point to an OSDF network of cache resource in some non-AWS server. Now we will prepare to access our data through PelicanFS by first telling PelicanFS where to find Sentinel-2 data in AWS, i.e. pointing it to Sentinel-2 data namespace in AWS. This creates a kind of file path to where OSDF caches data. We will have to do this for each asset URL as seen in the example above. Here is an example of how a new constructed OSDF path from an Asset URL looks like:
def getOSDFPath(url,AWSRegion='us-west-2'):
"""
Constructs an OSDF path from an asset's original URL.
Parameters:
- url: URL to convert.
Returns:
- OSDF path.
"""
return f'/aws-opendata/{AWSRegion}/sentinel-cogs{urllib.parse.urlparse(url).path}'
getOSDFPath(items[0].assets['nir'].href)'/aws-opendata/us-west-2/sentinel-cogs/sentinel-s2-l2a-cogs/53/W/MQ/2020/8/S2A_53WMQ_20200831_1_L2A/B08.tif'Now let’s try accessing this asset through PelicanFS, and opening the retrieved GeoTIFF file using Rasterio.
%%time
pelFS = PelicanFileSystem('pelican://osg-htc.org')
AWSRegionLst = ['us-east-1','us-east-2','us-central-1','us-central-2','us-west-1','us-west-2']
bandUrl = getOSDFPath(items[1].assets['nir'].href, 'us-west-2')
bandDS = rasterio.open(bandUrl, opener=pelFS)
bandDS.close()Discovery URL pelican://osg-htc.org/ does not match pelican://test/
CPU times: user 198 ms, sys: 35.7 ms, total: 234 ms
Wall time: 6.7 s
So we are able to read the raster through the PelicanFS using Rasterio. Let’s probe further to see which OSDF caches PelicanFS is routing us to!
pelFS._access_stats.get_responses(bandUrl)[0][-1].access_path'https://osdf1.newy32aoa.nrp.internet2.edu:8443/aws-opendata/us-west-2/sentinel-cogs/sentinel-s2-l2a-cogs/53/W/MQ/2020/8/S2A_53WMQ_20200831_0_L2A/B08.tif'Now we’ll pull a small trick and try to find out which OSDF resource PelicanFS found the cache, i.e. our raster file. This is helpful for us, because now we can easily point PelicanFS to this OSDF resource for all items in our catalog. Why are we doing this? We see from the two cells above that reading a single item’s asset takes ~8 second. Since we have 104 items each with 3 assets (the Red, NIR and SCL bands), that means at least ~24 seconds for each item, and for all items in our catalog. About 42 minutes in total, with potential additional network overhead time costs!
Now we will point all the URLs in our cache to https://osdf1.newy32aoa.nrp.internet2.edu:8443. We will also make a HTTP request to the new OSDF Cache URL and only point update our catalog with this new URL if the HTTP request is successful.
%%time
import warnings
warnings.filterwarnings('ignore')
pelFS = PelicanFileSystem('pelican://osg-htc.org')
itemsOSDFCache = items
for idx, item in enumerate(items): # start=1):
# print(f'Processing dataset #{idx}')
cacheCount = 0
for band in ['red','nir','scl']:
bandUrl = getOSDFPath(items[idx].assets[band].href)
# takes too long to access cache through PelicanFS unfortunately
# we can do a sneak peak of one of the items to see the OSDF location
# from which PelicanFS finds its cache then point the rest of our catalog to it!
'''
bandDS = rasterio.open(bandUrl, opener=pelFS)
if pelFS._access_stats.get_responses(bandUrl)[1]:
osdfCachePath = pelFS._access_stats.get_responses(bandUrl)[0][-1].access_path
# print(f'cache for dataset #{idx} found in {osdfCachePath} \n')
items[idx].assets[band].href = pelFS._access_stats.get_responses(bandUrl)[0][-1].access_path
cacheCount += 1
# close dataset!
bandDS.close()
'''
cacheOSDF = 'https://osdf1.newy32aoa.nrp.internet2.edu:8443'+bandUrl
with urllib.request.urlopen(cacheOSDF) as res:
if res.status == 200:
itemsOSDFCache[idx].assets[band].href = cacheOSDF
# print(f'{cacheCount} caches found for dataset #{idx} \n')
CPU times: user 722 ms, sys: 199 ms, total: 921 ms
Wall time: 8.44 s
Inspecting one of the items shows the that its assets point to the new OSDF URL!
items[23].assets['nir'].href'https://osdf1.newy32aoa.nrp.internet2.edu:8443/aws-opendata/us-west-2/sentinel-cogs/sentinel-s2-l2a-cogs/53/W/MQ/2020/8/S2A_53WMQ_20200811_0_L2A/B08.tif'Stacking STAC into lazy xarray objects¶
Now is the time to turn our “OSDF catalog” into data that we can analyze. We’ll do so by using the stackstac library to convert the STAC catalog to xarray data structures, and makes it possible to perform distributed computing with the help of dask. In any case, the resulting xarray data structures will be lazy, meaning that data is not loaded upfront, but only when needed. Because we have a large dataset [cite: compute size], lazy loading will be really helpful to optimize our resource usage.
%%time
s2Stack = stackstac.stack(itemsOSDFCache, assets=['red', 'nir', 'scl'],
bounds = aoiGeom.bounds,
gdal_env=stackstac.DEFAULT_GDAL_ENV.updated(
{'GDAL_HTTP_MAX_RETRY': 3,
'GDAL_HTTP_RETRY_DELAY': 5,
}),
epsg=4326,
# chunksize=(1, 1, 50, 50) # Original - many small chunks bad for plotting
chunksize=(1, -1, 100, 100)
).rename(
{'x': 'lon', 'y': 'lat'}).to_dataset(dim='band')
s2StackCPU times: user 207 ms, sys: 23.6 ms, total: 231 ms
Wall time: 233 ms
Section 2: NDVI analysis of water tracks and inter-tracks¶
Now we can continue our analysis!
Calculate NDVI¶
zeroMask = s2Stack['nir'] + s2Stack['red']
s2Stack['ndvi'] = (s2Stack.where(zeroMask != 0, np.nan)['nir'] - s2Stack.where(zeroMask != 0, np.nan)['red'])/\
(s2Stack.where(zeroMask != 0, np.nan)['nir'] + s2Stack.where(zeroMask != 0, np.nan)['red'])
# # Only keep ndvi and classification, but know you can save things like 'visible' or other fun rasters!
s2Stack = s2Stack[['ndvi', 'scl']]
s2Stack = s2Stack.drop_vars([c for c in s2Stack.coords if not (c in ['time', 'lat', 'lon'])])
s2StackTest on the centroid¶
%%time
s2Point = s2Stack.interp(lat=lat, lon=lon,method='nearest')
s2Df = s2Point.to_dataframe()
s2DfFilt = s2Df[(s2Df['scl'] == 4) | (s2Df['scl'] == 5)]
fig, ax = plt.subplots()
s2DfFilt['ndvi'].plot(label='unfiltered',
marker='o',
# linestyle='--',
markersize=2, ax=ax)
ax.set_ylim(-1.0,5.0)
plt.show()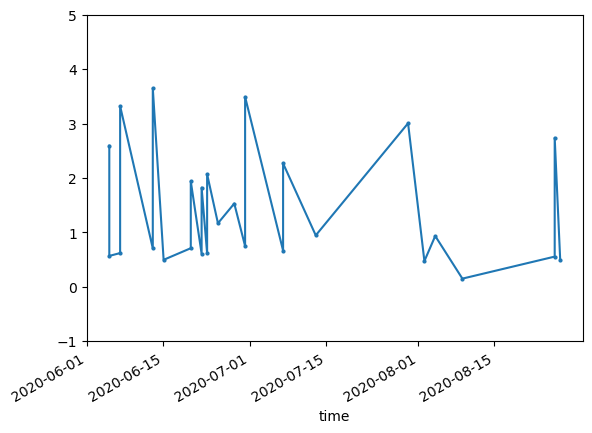
CPU times: user 24.7 s, sys: 1.58 s, total: 26.3 s
Wall time: 21.1 s
Fascinating. What happened in late July, early August 2020? Let’s take a look at an asset from the collection during that time period.
pics = {}
from datetime import datetime
for item in items:
item_dict = {}
item_dict['date'] = item.properties['datetime']
item_dict['pic'] = item.assets['visual'].href
item_dict['thumb'] = item.assets['thumbnail'].href
pics[item.id] = item_dict%%time
from rasterio.plot import show
with rasterio.open(pics['S2A_53WMQ_20200804_1_L2A']['pic']) as dataset:
show(dataset)
CPU times: user 13.9 s, sys: 7.12 s, total: 21.1 s
Wall time: 31.3 s
That’ll do it! (this is a fire burning the larch forests of the eastern Siberia taiga)
Plot the whole stack?¶
Mosaic by date¶
s2StackMosaic = s2Stack.groupby('time.date').median(dim='time')
# s2StackMosaic = sentinel_stack_mosaicked.rename({'date': 'time'})
# sentinel_stack_mosaicked['time'] = sentinel_stack_mosaicked['time'].astype('datetime64[ns]')Day of year makes it easier for a linear trend analysis!
day_of_year = xr.DataArray(
s2StackMosaic['date'].astype('datetime64[ns]').dt.dayofyear,
coords={'date': s2StackMosaic['date']},
dims='date',
name='day_of_year'
)
s2StackMosaic = s2StackMosaic.assign_coords({'day_of_year': day_of_year})
s2StackMosaicNow we can look at cool pictures by date
s2StackMosaic['ndvi'][1].plot.imshow(vmin=-1.0, vmax=1.0)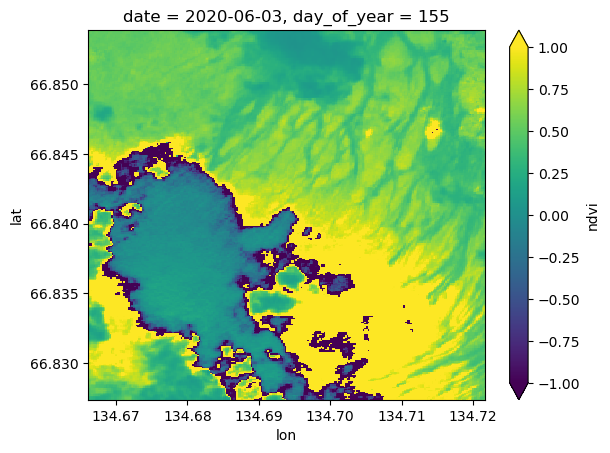
Mask out undesireable pixels in the stack according to the scene classification layer¶
s2StackMosaic['scl'][0].plot.imshow(cmap='Set1')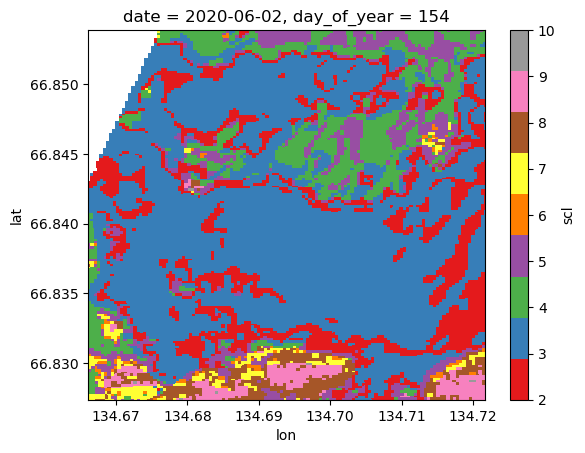
Google ‘sentinel 2 scene classification layer’. You’ll see that 4 and 5 are coded for vegetated and not vegetated. Conservatively, everything else is trash for interpreting NDVI.
ndviMasked = s2StackMosaic['ndvi'].where(s2StackMosaic['scl'].isin([4, 5]))
ndviMasked = ndviMasked.where(ndviMasked >= -1.0)
ndviMasked = ndviMasked.where(ndviMasked <= 1.0)
ndviMasked[0].plot.imshow(
# vmin=-1.0, vmax=1.0
)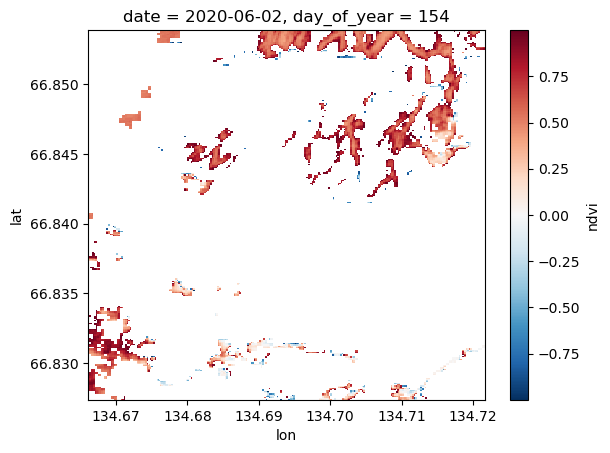
Ah yes, that’s better.
%%time
meanNDVIDoY = ndviMasked.mean(dim=['lat', 'lon'], skipna=True).to_dataframe(name='mean_ndvi').reset_index()
meanNDVIDoY.head()CPU times: user 50.7 s, sys: 4.77 s, total: 55.5 s
Wall time: 33.5 s
meanNDVIDoY.plot.scatter(x='day_of_year', y='mean_ndvi')<Axes: xlabel='day_of_year', ylabel='mean_ndvi'>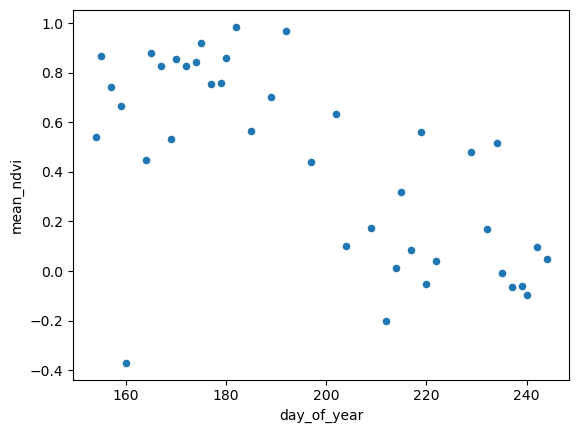
Ok, so now we’re able to detect this somehow automatically. It would be helpful to cross-referencing this against some climate (in this case it’s burned, not climate, which are related but also maybe checking against some fire database or product too).
Do a trendline fit¶
What if we could visualize the pixelwise trend in greening and browning over a season? Let’s take a linear trend for each pixel’s NDVI across the year (hence why day of year is a useful variable here).
%%time
fit = ndviMasked.polyfit(dim='day_of_year', deg=1)
slopes = fit['polyfit_coefficients'].sel(degree=1)
slopes.plot.imshow(
cmap='coolwarm_r',
vmin=-.01,
vmax=.01)
CPU times: user 1min 7s, sys: 5.42 s, total: 1min 12s
Wall time: 46.2 s
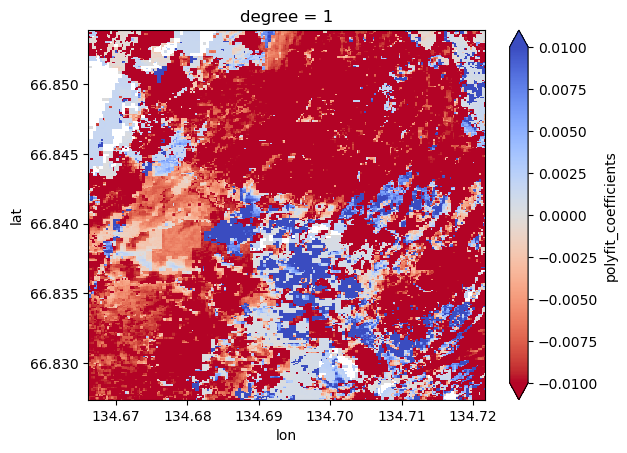
This is now a great raster to play around with in GIS if you choose. A lot of those red streaks are the flowpaths we’re intersted in (water tracks) so it’s interesting that they got browner over the growing season compared to the intertrack areas which are generally positive (got greener over the growing season).
What’s Next?¶
In the near future, this notebook will:
Address PelicanFS bottlenecks during reading of cache metadata.
Use a larger AOI and longer time period to see this anylysis over multiple years.
With a larger AOI and longer time series, we’ll have more data, wo we’ll experiment with distributed computing with Dask.