
Introducción a Pandas¶
Pandas es una librería de código abierto en Python diseñada para facilitar la manipulación y el análisis de datos estructurados, especialmente aquellos en formato tabular (como hojas de cálculo o bases de datos).
Proporciona estructuras de datos potentes y flexibles, como DataFrame y Series, que permiten trabajar de forma eficiente con información numérica y etiquetada.
Objetivo¶
Este cuadernillo tiene como objetivo introducir los conceptos fundamentales del uso de la librería Pandas en Python, una herramienta esencial para el análisis de datos. Aprenderás a cargar, explorar, filtrar y visualizar conjuntos de datos en formato tabular de forma práctica y reproducible.
📚 Descripción general¶
Al finalizar este cuadernillo, serás capaz de:
Entender las estructuras de datos clave en Pandas:
SeriesyDataFrameCargar datos desde archivos externos (como
.csv)Acceder, seleccionar y filtrar datos usando etiquetas o posiciones
Realizar análisis exploratorio y estadísticas básicas
Generar visualizaciones rápidas con los datos
✅ Requisitos previos¶
| Concepto | Importancia | Notas |
|---|---|---|
| Introducción a Python | Necesario | Tipos de datos, funciones, operadores |
| Introducción a JupyterLab | Necesario | Navegación y ejecución de celdas |
| Fundamentos de NumPy | Necesario | Arrays, operaciones vectorizadas |
⏱️ Tiempo estimado de aprendizaje: 20–25 minutos
✍️ Formato: interactivo, ejecuta y modifica el código a medida que avanzas
1. ¿Qué es Pandas?¶
Pandas es una biblioteca de Python para el análisis y manipulación de datos estructurados.
Su nombre viene de “panel data”, un término utilizado en economía para referirse a conjuntos de datos multidimensionales.
Está diseñada para facilitar el trabajo con:
Tablas similares a hojas de cálculo (como archivos
.csv, Excel, SQL, etc.)Series temporales
Datos con etiquetas (columnas y filas con nombres)
Pandas proporciona dos estructuras de datos principales:
| Objeto | Descripción |
|---|---|
Series | Columna de datos con índice (unidimensional) |
DataFrame | Tabla de datos con filas y columnas (bidimensional) |
Estas estructuras permiten trabajar con datos de manera intuitiva, utilizando etiquetas en lugar de posiciones numéricas.
Importamos Pandas
import pandas as pd1.1. Crear una Series¶
Una Series es como una columna en Excel. Cada elemento tiene un índice asociado:
numeros = pd.Series([10, 20, 30, 40])
print(numeros)0 10
1 20
2 30
3 40
dtype: int64
📝 ¿Qué significa esto?
A la izquierda se muestra el índice (por defecto empieza en 0).
A la derecha está el valor asociado a cada índice.
La última línea
dtype: int64indica que los valores son enteros de 64 bits (int64), un tipo de dato numérico común en análisis de datos.
✅ Las
Seriespermiten usar índices personalizados, filtrar datos y aplicar operaciones matemáticas, lo que las hace muy útiles para trabajar con columnas individuales en unDataFrame.
1.2. Crear un DataFrame¶
Un DataFrame es una tabla de datos con filas y columnas:
datos = {
"País": ["Colombia", "Brasil", "México"],
"Población (millones)": [51.52, 212.6, 126.7]
}
df = pd.DataFrame(datos)print(df) País Población (millones)
0 Colombia 51.52
1 Brasil 212.60
2 México 126.70
La salida del DataFrame es una tabla que contiene:
Una columna de índice a la izquierda: en este caso, Pandas ha asignado automáticamente los índices
0,1y2para cada fila.La columna “País”, que contiene cadenas de texto (
str), con los nombres de los países.La columna “Población (millones)”, que contiene valores numéricos con decimales (
float), indicando la población en millones para cada país.
Esta estructura es muy similar a una hoja de cálculo de Excel, donde:
Cada fila representa una entrada o registro.
Cada columna representa una variable o característica de los datos.
✅ Los índices de fila (0, 1, 2) pueden personalizarse más adelante para que usen, por ejemplo, los nombres de los países.
Puedes acceder a esta tabla como conjunto completo o trabajar con columnas y filas específicas, como veremos en las siguientes secciones.
2. Trabajando con DataFrames¶
El objeto DataFrame es la estructura central de Pandas. Nos permite trabajar con datos tabulares de forma eficiente y expresiva.
2.1. ¿Cómo se ve un DataFrame?¶
Podemos construir un DataFrame fácilmente a partir de un diccionario de Python. Aquí un ejemplo con temperaturas promedio de algunas ciudades en enero:
ciudades = {
"Ciudad": [
"Bogotá", "Medellín", "Barranquilla", "Cali", "Pereira",
"Manizales", "Santa Marta", "Cartagena", "Tunja", "Bucaramanga"
],
"Temp. Promedio (°C)": [14.5, 22.3, 27.6, 24.0, 22.0, 18.0, 28.5, 28.0, 13.0, 23.5],
"Altitud (msnm)": [2640, 1475, 18, 1000, 1341, 2150, 6, 2, 2820, 959]
}
df = pd.DataFrame(ciudades)df
🔎 En esta imagen (inspirada en Pythia Foundations) puedes ver cómo:
Cada fila representa una observación (una ciudad).
Cada columna representa una variable (temperatura, altitud).
La columna gris a la izquierda representa el índice de las filas.
✅ Este formato es muy útil para trabajar con datos tabulares como archivos .csv, bases de datos o resultados experimentales.
2.2. Propiedades del DataFrame¶
Pandas proporciona varios atributos para entender rápidamente la estructura de un DataFrame.
🔢 Índices de las filas
Muestra el rango o tipo de índice que se está utilizando para las filas. Por defecto, es un rango numérico.
df.index # Índices de filaRangeIndex(start=0, stop=10, step=1)🏷️ Nombres de las columnas
Devuelve una lista con los nombres de todas las columnas del DataFrame.
df.columns # Nombres de columnasIndex(['Ciudad', 'Temp. Promedio (°C)', 'Altitud (msnm)'], dtype='object')📐 Dimensiones del DataFrame
Nos dice cuántas filas y columnas tiene el DataFrame.
df.shape # Tamaño: (número de filas, columnas)(10, 3)🧪 Tipos de datos por columna
Nos permite ver el tipo de datos (enteros, flotantes, texto, etc.) de cada columna. Muy útil para asegurarnos de que los datos se cargaron correctamente.
df.dtypes # Tipo de dato de cada columnaCiudad object
Temp. Promedio (°C) float64
Altitud (msnm) int64
dtype: object2.3. Cargar datos desde un archivo CSV 📂¶
En la práctica, rara vez construiremos DataFrames manualmente. Lo más común es cargar datos desde archivos externos.
Pandas facilita la lectura de archivos CSV con pd.read_csv():
# Ejemplo: cargar ubicaciones de radares meteorológicos
estaciones = pd.read_csv("../data/radar_locations.csv")
print("Primeras filas del archivo:")
estaciones.head()Primeras filas del archivo:
💡 Otros formatos soportados por Pandas:
Excel:
pd.read_excel("archivo.xlsx")JSON:
pd.read_json("archivo.json")SQL:
pd.read_sql("SELECT * FROM tabla", conexion)
Parámetros útiles de pd.read_csv():
sep=";": cambiar separador (por defecto es coma)encoding="utf-8": especificar codificaciónindex_col=0: usar primera columna como índicena_values=["NA", "N/A"]: valores que representan datos faltantes
3. Series dentro de un DataFrame¶
Ya vimos que una Series es una estructura unidimensional con índice, similar a una columna de Excel. En un DataFrame, cada columna es internamente una Series.
Veamos cómo podemos trabajar con ellas:
3.1. Acceder a una columna (como Series)¶
Podemos acceder a una columna usando su nombre, lo que nos devuelve una Series:
df["Temp. Promedio (°C)"]0 14.5
1 22.3
2 27.6
3 24.0
4 22.0
5 18.0
6 28.5
7 28.0
8 13.0
9 23.5
Name: Temp. Promedio (°C), dtype: float64También se puede usar la notación de atributo si el nombre no tiene espacios:
df.Ciudad # Igual a df["Ciudad"]0 Bogotá
1 Medellín
2 Barranquilla
3 Cali
4 Pereira
5 Manizales
6 Santa Marta
7 Cartagena
8 Tunja
9 Bucaramanga
Name: Ciudad, dtype: object3.2. Acceder a una fila específica¶
En Pandas, cada fila de un DataFrame representa una observación, como un registro en una base de datos o una fila de Excel. Para acceder a estas observaciones completas, usamos dos métodos muy útiles:
🧭 .loc[]: acceso por etiqueta¶
df.loc[0] # Por etiqueta (funciona bien si el índice es texto)Ciudad Bogotá
Temp. Promedio (°C) 14.5
Altitud (msnm) 2640
Name: 0, dtype: object🟡 Este método es útil si tu índice no es numérico, por ejemplo:
df.index = ["bog", "med", "bar", "cal", "per", "man", "sam", "car", "tun", "buc"]
df.loc["med"]Ciudad Medellín
Temp. Promedio (°C) 22.3
Altitud (msnm) 1475
Name: med, dtype: object.iloc[]: acceso por posición entera¶
Usamos .iloc[] cuando queremos acceder a una fila por su posición (sin importar el valor del índice).
df.iloc[0] # Por posiciónCiudad Bogotá
Temp. Promedio (°C) 14.5
Altitud (msnm) 2640
Name: bog, dtype: object💡 Este método siempre funciona, independientemente del tipo de índice que tenga tu DataFrame.
3.3. Filtrar y seleccionar datos por condiciones¶
Una de las fortalezas de Pandas es la facilidad para seleccionar subconjuntos de datos usando condiciones lógicas. A esto se le llama “filtrado”.
Filtrar filas que cumplan una condición¶
Por ejemplo, si queremos ver solo las ciudades con temperatura mayor a 20°C:
df[df["Temp. Promedio (°C)"] > 20]📌 Esto devuelve un nuevo DataFrame con las filas que cumplen la condición.
Filtrar usando múltiples condiciones¶
Si queremos ver ciudades con temperatura mayor a 20°C y altitud menor a 2000 msnm:
df[
(df["Temp. Promedio (°C)"] > 20) &
(df["Altitud (msnm)"] < 2000)
]⚠️ Las condiciones múltiples deben ir entre paréntesis
Y usamos & (y), | (o), ~ (no).
Filtrar y seleccionar columnas específicas 🗂️¶
Si además queremos ver solo algunas columnas, lo combinamos con doble corchete:
df[
(df["Temp. Promedio (°C)"] > 20)
][["Ciudad", "Altitud (msnm)"]]También puedes usar .loc[]¶
.loc permite combinar condiciones con selección explícita de columnas:
df.loc[
df["Temp. Promedio (°C)"] > 20,
["Ciudad", "Temp. Promedio (°C)"]
]✅ Resumen rápido:
| Acción | Ejemplo |
|---|---|
| Filtrar filas | df[df["col"] > valor] |
| Varias condiciones | (cond1) & (cond2) |
| Filtrar y seleccionar columnas | df[cond][["col1", "col2"]] |
Con .loc[] | df.loc[cond, ["col1", "col2"]] |
3.4 📊 Estadísticas básicas y resumen de datos¶
Una vez cargamos nuestros datos, es importante poder resumirlos estadísticamente para tener una idea general de su distribución, tendencias y valores atípicos.
📌 Resumen estadístico rápido¶
Usa .describe() para obtener un resumen estadístico de todas las columnas numéricas:
df.describe()📋 Incluye: media, desviación estándar, mínimo, máximos y cuartiles.
Estadísticas comunes¶
Puedes calcular medidas específicas sobre una columna (o Series):
df["Temp. Promedio (°C)"].mean() # Medianp.float64(22.14)df["Temp. Promedio (°C)"].std() # Desviación estándar5.467113802851861df["Temp. Promedio (°C)"].min() # Mínimo13.0df["Temp. Promedio (°C)"].max() # Máximo28.5df["Temp. Promedio (°C)"].median() # Mediana22.9También puedes hacerlo sobre todo el DataFrame:
df.mean()
TypeError: Could not convert ['BogotáMedellínBarranquilla'] to numericLas funciones estadísticas como
.mean(), .std() o .sum() solo funcionan con columnas numéricas.Si tu DataFrame contiene columnas con texto (por ejemplo, nombres de ciudades), deberías filtrar las columnas antes de aplicar operaciones estadísticas:
df.select_dtypes(include="number")Esto previene errores y asegura que las operaciones matemáticas se realicen correctamente.
df.select_dtypes(include="number").mean()Temp. Promedio (°C) 22.14
Altitud (msnm) 1241.10
dtype: float644. 📊 Análisis exploratorio de datos¶
Una vez que tienes tus datos cargados en un DataFrame, Pandas ofrece muchas herramientas para explorarlos rápidamente.
4.1. Ver las primeras y últimas filas¶
Es común empezar viendo un vistazo general de los datos. Para esto usamos .head() y .tail(), que nos permiten inspeccionar las primeras y últimas filas del DataFrame.
df.head() # Muestra las primeras 5 filasdf.tail() # Muestra las últimas 5 filasPuedes pasar un número como argumento para ver más o menos filas:
df.head(2) # Primeras 2 filas4.2. Información general del DataFrame¶
Esta función es útil para entender la estructura del DataFrame: cuántas columnas hay, qué tipos de datos contiene, si hay valores nulos, etc.
df.info()<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, bog to buc
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Ciudad 10 non-null object
1 Temp. Promedio (°C) 10 non-null float64
2 Altitud (msnm) 10 non-null int64
dtypes: float64(1), int64(1), object(1)
memory usage: 620.0+ bytes
Este comando te muestra:
El número de entradas (filas)
El número de columnas
El tipo de dato de cada columna
Cuántos datos no nulos tiene cada columna
📐 4.3. Estadísticas rápidas¶
describe() te da una descripción estadística de las columnas numéricas, ideal para tener una idea de la distribución de los datos.
df.describe()Devuelve:
Conteo (
count)Media (
mean)Desviación estándar (
std)Mínimo, percentiles (25%, 50%, 75%) y máximo
📎 4.4. Media, mínimo, máximo y más¶
Puedes aplicar funciones estadísticas específicas como la media, mínimo, máximo y desviación estándar a columnas individuales:
df["Temp. Promedio (°C)"].mean()np.float64(22.14)df["Temp. Promedio (°C)"].min()13.0df["Temp. Promedio (°C)"].max()28.5df["Temp. Promedio (°C)"].std()5.467113802851861📊 5. Visualizaciones rápidas¶
Una de las ventajas de Pandas es que permite crear visualizaciones rápidas sin necesidad de importar explícitamente librerías de gráficos como matplotlib.
5.1. Gráfico de líneas¶
Ideal para observar series temporales o tendencias.
df["Temp. Promedio (°C)"].plot(title="Temperatura promedio por ciudad", marker="o");
📊 5.2. Histograma¶
Útil para ver la distribución de los datos numéricos.
df["Temp. Promedio (°C)"].plot.hist(bins=5, title="Distribución de temperaturas");
5.3. Diagrama de cajas (Boxplot)¶
Muestra estadísticas como mediana, cuartiles y posibles valores atípicos.
df[["Temp. Promedio (°C)"]].plot.box(title="Resumen estadístico");
📊 5.4. Gráfico de barras¶
Perfecto para comparar valores entre categorías, como ciudades.
df["Temp. Promedio (°C)"].plot.bar(title="Temperatura promedio por ciudad");
Si prefieres que se muestre horizontal, puedes usar .barh():
df["Temp. Promedio (°C)"].plot.barh(title="Temperatura promedio por ciudad");
🌀 5.5. Gráfico de dispersión (Scatter)¶
Cuando quieres analizar la relación entre dos variables numéricas.
df.plot.scatter(x="Altitud (msnm)", y="Temp. Promedio (°C)", title="Temperatura vs Altitud");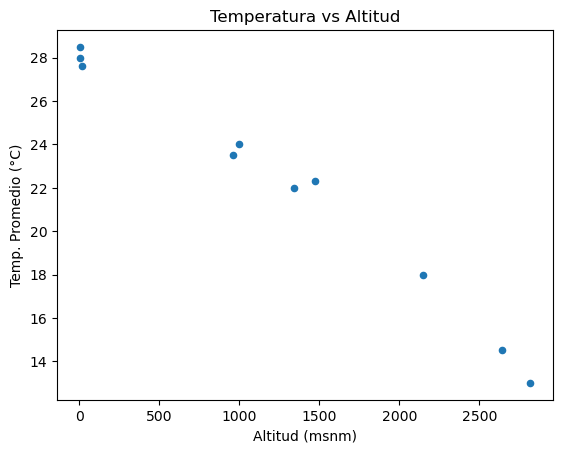
6. 🎯 Práctica guiada¶
Ahora es tu turno de aplicar lo aprendido. Completa los siguientes ejercicios:
Ejercicio 1: Crear tu propio DataFrame 🟢¶
Crea un DataFrame con 5 países latinoamericanos de tu elección e incluye:
Nombre del país
Población (millones)
PIB per cápita (USD)
Esperanza de vida (años)
# Tu código aquíEjercicio 2: Exploración básica 🟢¶
Usando el DataFrame de ciudades colombianas (df):
¿Cuál es la temperatura promedio de todas las ciudades?
¿Cuántas ciudades tienen altitud mayor a 1.500 msnm?
Muestra solo las ciudades con temperatura entre 20°C y 25°C
¿Cuál es la ciudad con mayor altitud?
# Tu código aquíEjercicio 3: Visualización 🟡¶
Crea un gráfico de dispersión que muestre la relación entre altitud y temperatura.
Preguntas:
¿Qué patrón observas?
¿Las ciudades más altas tienden a ser más frías o más calientes?
¿Hay alguna ciudad que parezca inusual (outlier)?
# Tu código aquíEjercicio 4: Filtrado avanzado 🟡¶
Filtra las ciudades que cumplan TODAS estas condiciones:
Temperatura menor a 18°C
Altitud mayor a 2.000 msnm
Población mayor a 500.000 habitantes
# Tu código aquí7. 📊 Proyecto final: Análisis climático de Colombia¶
Aplica todo lo aprendido en este análisis integrador.
Contexto: Eres analista de datos en el IDEAM y necesitas preparar un reporte sobre las características térmicas de las principales ciudades colombianas.
Datos: Usa el DataFrame df que creamos con las ciudades colombianas.
Tareas:
Exploración inicial: Muestra las primeras 5 filas, verifica los tipos de datos con
.info()y calcula estadísticas descriptivas con.describe()Análisis de temperaturas: Calcula la temperatura promedio nacional, identifica las 3 ciudades más frías y las 3 más calientes, determina qué porcentaje de ciudades tiene temperatura > 25°C
Análisis de altitud: Calcula la altitud promedio y clasifica las ciudades en: Bajas (< 1.000 msnm), Medias (1.000-2.500 msnm), Altas (> 2.500 msnm)
Análisis de relaciones: Crea un scatter plot de altitud vs temperatura y calcula la temperatura promedio por rango de altitud
Identificar casos especiales: Encuentra ciudades costeras (altitud < 100 msnm) con temperatura < 25°C y ciudades andinas (altitud > 2.000 msnm) con temperatura > 15°C
Visualizaciones finales: Crea un histograma de distribución de temperaturas, bar chart de las 10 ciudades más pobladas, y boxplot de temperaturas
Conclusiones: Escribe 3 conclusiones basadas en tu análisis
# Tu código aquí
# Desarrolla cada análisis paso a paso💡 Pista: Combina lo que aprendiste sobre selección (.loc[]), filtrado (boolean indexing), estadísticas (.mean(), .max()), y visualizaciones (.plot(), .hist()).
✅ Auto-evaluación¶
Al finalizar este cuadernillo deberías poder:
Explicar la diferencia entre Series y DataFrame
Crear un DataFrame desde un diccionario
Cargar datos desde un archivo CSV usando
pd.read_csv()Acceder a columnas y filas usando
.loc[]e.iloc[]Filtrar datos usando condiciones simples y múltiples
Calcular estadísticas básicas con
.mean(),.describe(), etc.Crear visualizaciones rápidas con
.plot(),.hist(),.scatter()Interpretar gráficos para extraer conclusiones sobre los datos
Si puedes marcar todos estos puntos, ¡estás listo para trabajar con datos tabulares reales! 🎉
Conclusión y recursos útiles¶
En este cuadernillo aprendiste los fundamentos del uso de Pandas para trabajar con datos tabulares:
Qué son las
Seriesy losDataFrameCómo acceder y filtrar datos usando etiquetas o posiciones
Cómo realizar análisis exploratorio y estadísticas básicas
Cómo generar visualizaciones rápidas con tus datos
Pandas es una herramienta poderosa y flexible que se utiliza ampliamente en la ciencia de datos, la investigación, el análisis financiero y muchas otras disciplinas. Con esta base, ya estás listo para realizar análisis más complejos.
Recursos adicionales¶
¿Quieres seguir aprendiendo? En el próximo cuadernillo veremos cómo trabajar con datos multidimensionales usando Xarray. 📦🌎
Fuentes y Referencias¶
Rose, B. E. J., Kent, J., Tyle, K., Clyne, J., Banihirwe, A., Camron, D., May, R., Grover, M., Ford, R. R., Paul, K., Morley, J., Eroglu, O., Kailyn, L., & Zacharias, A. (2023). Pythia Foundations (Version v2023.05.01) Rose et al. (2023)
- Rose, B., Kent, J., Tyle, K., Clyne, Banihirwe, A., Camron, D., Ford, R., Morley, J., Grover, M., Eroglu, O., Paul, K., May, R., Lkailynncar, Irving, D., Uieda, L., Ojaybee, Blain, P., & Moon, Z. (2023). ProjectPythia/pythia-foundations: v2023.05.01. Zenodo. 10.5281/ZENODO.7884572