
Plotting HRRR 2-meter temperatures
Overview
Access archived HRRR data hosted on AWS in Zarr format
Visualize one of the variables (2m temperature) at an analysis time
Prerequisites
Concepts |
Importance |
Notes |
|---|---|---|
Xarray Lessons 1-9 |
Necessary |
Time to learn: 30 minutes
Imports
import xarray as xr
import s3fs
import metpy
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import pandas as pd
What is Zarr?
Gridded datasets, especially those produced by operational meteorological centers such as NCEP and ECMWF, are typically in NetCDF and GRIB formats. Zarr is a relatively new data format. It is particularly relevant in the following two scenarios:
Datasets that are stored in what’s called object store. This is a commonly-used storage method for cloud providers, such as Amazon, Google, and Microsoft.
Datasets that are typically too large to load into memory all at once.
Xarray supports the Zarr format in addition to NetCDF and GRIB. The Pangeo project specifically recommends Zarr as the Xarray-amenable data format of choice in the cloud:
“Our current preference for storing multidimensional array data in the cloud is the Zarr format. Zarr is a new storage format which, thanks to its simple yet well-designed specification, makes large datasets easily accessible to distributed computing. In Zarr datasets, the arrays are divided into chunks and compressed. These individual chunks can be stored as files on a filesystem or as objects in a cloud storage bucket. The metadata are stored in lightweight .json files. Zarr works well on both local filesystems and cloud-based object stores. Existing datasets can easily be converted to zarr via xarray’s zarr functions.”
Access archived HRRR data hosted on AWS in Zarr format
For a number of years, the Mesowest group at the University of Utah has hosted an archive of data from NCEP’s High Resolution Rapid Refresh model. This data, originally in GRIB-2 format, has been converted into Zarr and is freely available “in the cloud”, on Amazon Web Service’s Simple Storage Service, otherwise known as S3. Data is stored in S3 in a manner akin to (but different from) a Linux filesystem, using a bucket and object model.
To interactively browse the contents of this archive, go to this link: HRRRZarr File Browser on AWS
To access Zarr-formatted data stored in an S3 bucket, we follow a 3-step process:
Create URL(s) pointing to the bucket and object(s) that contain the data we want
Create map(s) to the object(s) with the s3fs library’s
S3MapmethodPass the map(s) to Xarray’s
open_datasetoropen_mfdatasetmethods, and specifyzarras the format, via theengineargument.
open_mfdataset method and pass in two AWS S3 file references to these two corresponding directories.
Create the URLs
date = '20210214'
hour = '12'
var = 'TMP'
level = '2m_above_ground'
url1 = 's3://hrrrzarr/sfc/' + date + '/' + date + '_' + hour + 'z_anl.zarr/' + level + '/' + var + '/' + level
url2 = 's3://hrrrzarr/sfc/' + date + '/' + date + '_' + hour + 'z_anl.zarr/' + level + '/' + var
print(url1)
print(url2)
s3://hrrrzarr/sfc/20210214/20210214_12z_anl.zarr/2m_above_ground/TMP/2m_above_ground
s3://hrrrzarr/sfc/20210214/20210214_12z_anl.zarr/2m_above_ground/TMP
Create the S3 maps from the S3 object store.
fs = s3fs.S3FileSystem(anon=True)
file1 = s3fs.S3Map(url1, s3=fs)
file2 = s3fs.S3Map(url2, s3=fs)
Use Xarray’s open_mfdataset to create a Dataset from these two S3 objects.
ds = xr.open_mfdataset([file1,file2], engine='zarr')
Examine the dataset.
ds
<xarray.Dataset> Size: 4MB
Dimensions: (projection_y_coordinate: 1059,
projection_x_coordinate: 1799)
Coordinates:
* projection_x_coordinate (projection_x_coordinate) float64 14kB -2.698e+0...
* projection_y_coordinate (projection_y_coordinate) float64 8kB -1.587e+06...
Data variables:
TMP (projection_y_coordinate, projection_x_coordinate) float16 4MB dask.array<chunksize=(150, 150), meta=np.ndarray>
forecast_period timedelta64[ns] 8B ...
forecast_reference_time datetime64[ns] 8B ...
height float64 8B ...
pressure float64 8B ...
time datetime64[ns] 8B ...Get the map projection for the HRRR, which is stored in the grid folder in the AWS bucket.
HRRR_proj = pd.read_json ("https://hrrrzarr.s3.amazonaws.com/grid/projparams.json", orient="index")
HRRR_proj
| 0 | |
|---|---|
| a | 6371229 |
| b | 6371229 |
| proj | lcc |
| lon_0 | 262.5 |
| lat_0 | 38.5 |
| lat_1 | 38.5 |
| lat_2 | 38.5 |
lat_0 = HRRR_proj.loc['lat_0'].astype('float32').squeeze()
lat_1 = HRRR_proj.loc['lat_1'].astype('float32').squeeze()
lat_2 = HRRR_proj.loc['lat_2'].astype('float32').squeeze()
lon_0 = HRRR_proj.loc['lon_0'].astype('float32').squeeze()
a = HRRR_proj.loc['a'].astype('float32').squeeze()
b = HRRR_proj.loc['b'].astype('float32').squeeze()
projData= ccrs.LambertConformal(central_longitude=lon_0, central_latitude=lat_0,
standard_parallels=[lat_1,lat_2],
globe=ccrs.Globe(semimajor_axis=a, semiminor_axis=b))
Globe in Cartopy with these values.
Examine the dataset’s coordinate variables. Each x- and y- value represents distance in meters from the central latitude and longitude.
ds.coords
Coordinates:
* projection_x_coordinate (projection_x_coordinate) float64 14kB -2.698e+0...
* projection_y_coordinate (projection_y_coordinate) float64 8kB -1.587e+06...
Create an object pointing to the dataset’s data variable.
airTemp = ds.TMP
When we examine the object, we see that it is a special type of DataArray … a DaskArray.
airTemp
<xarray.DataArray 'TMP' (projection_y_coordinate: 1059,
projection_x_coordinate: 1799)> Size: 4MB
dask.array<open_dataset-TMP, shape=(1059, 1799), dtype=float16, chunksize=(150, 150), chunktype=numpy.ndarray>
Coordinates:
* projection_x_coordinate (projection_x_coordinate) float64 14kB -2.698e+0...
* projection_y_coordinate (projection_y_coordinate) float64 8kB -1.587e+06...
Attributes:
GRIB_PARAM: [2, 0, 0, 0]
long_name: 2m_above_ground/TMP
units: KSidetrip: Dask
open_mfdataset, the resulting objects are Dask objects.
MetPy supports Dask arrays, and so performing a unit conversion is straightforward.
airTemp = airTemp.metpy.convert_units('degC')
Verify that the object has the unit change
airTemp
<xarray.DataArray 'TMP' (projection_y_coordinate: 1059,
projection_x_coordinate: 1799)> Size: 4MB
<Quantity(dask.array<truediv, shape=(1059, 1799), dtype=float16, chunksize=(150, 150), chunktype=numpy.ndarray>, 'degree_Celsius')>
Coordinates:
* projection_x_coordinate (projection_x_coordinate) float64 14kB -2.698e+0...
* projection_y_coordinate (projection_y_coordinate) float64 8kB -1.587e+06...
Attributes:
GRIB_PARAM: [2, 0, 0, 0]
long_name: 2m_above_ground/TMPSimilar to what we did for datasets whose projection-related coordinates were latitude and longitude, we define objects pointing to x and y now, so we can pass them to the plotting functions.
x = airTemp.projection_x_coordinate
y = airTemp.projection_y_coordinate
Visualize 2m temperature at an analysis time
First, just use Xarray’s plot function to get a quick look to verify that things look right.
airTemp.plot(figsize=(11,8.5))
<matplotlib.collections.QuadMesh at 0x7f01853384d0>
To facilitate the bounds of the contour intervals, obtain the min and max values from this DataArray.
DataArray in Xarray. If we want to perform a computation on this array, e.g. calculate the mean, min, or max, note that we don't get a result straightaway ... we get another Dask array.
airTemp.min()
<xarray.DataArray 'TMP' ()> Size: 2B <Quantity(dask.array<_nanmin_skip-aggregate, shape=(), dtype=float16, chunksize=(), chunktype=numpy.ndarray>, 'degree_Celsius')>
compute function to actually trigger the computation.
minTemp = airTemp.min().compute()
maxTemp = airTemp.max().compute()
minTemp.values, maxTemp.values
(array(-42.38, dtype=float16), array(26., dtype=float16))
Based on the min and max, define a range of values used for contouring. Let’s invoke NumPy’s floor and ceil(ing) functions so these values conform to whatever variable we are contouring.
fint = np.arange(np.floor(minTemp.values),np.ceil(maxTemp.values) + 2, 2)
fint
array([-43., -41., -39., -37., -35., -33., -31., -29., -27., -25., -23.,
-21., -19., -17., -15., -13., -11., -9., -7., -5., -3., -1.,
1., 3., 5., 7., 9., 11., 13., 15., 17., 19., 21.,
23., 25., 27.])
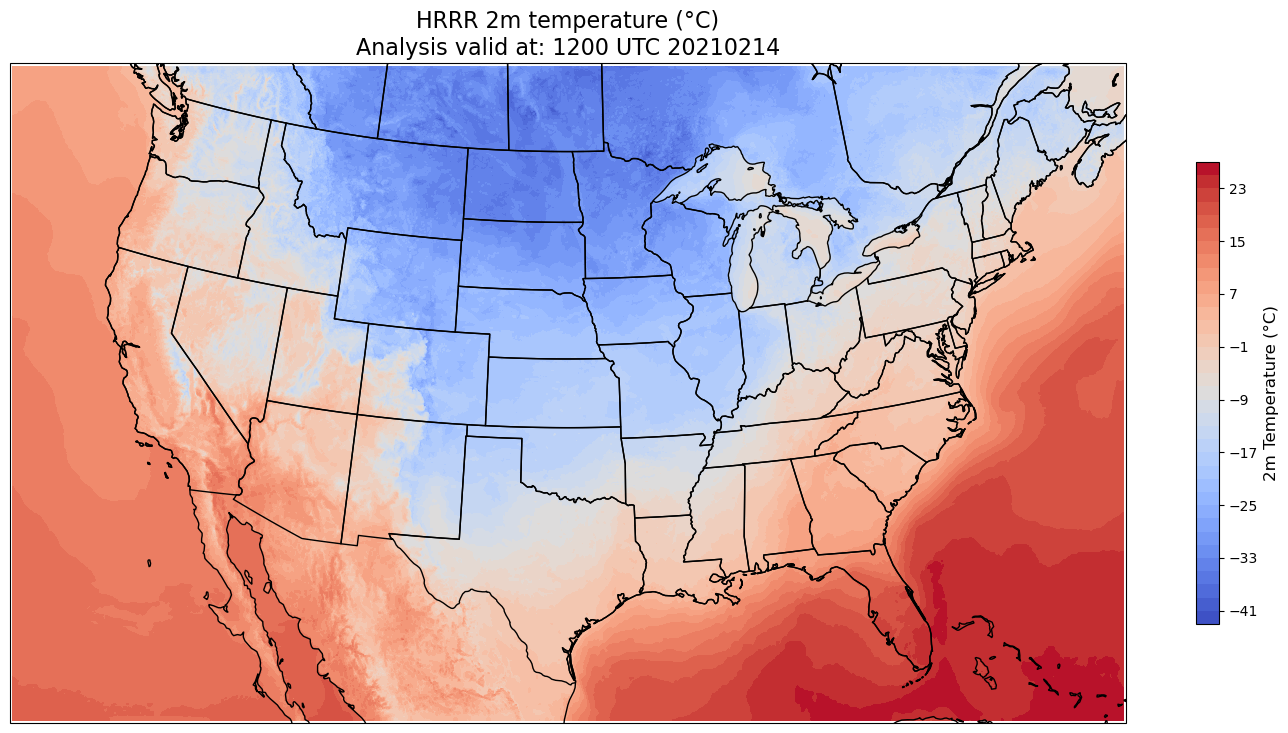
Plot the map
We’ll define the plot extent to nicely encompass the HRRR’s spatial domain.
latN = 50.4
latS = 24.25
lonW = -123.8
lonE = -71.2
res = '50m'
fig = plt.figure(figsize=(18,12))
ax = fig.add_subplot(1,1,1,projection=projData)
ax.set_extent ([lonW,lonE,latS,latN],crs=ccrs.PlateCarree())
ax.add_feature(cfeature.COASTLINE.with_scale(res))
ax.add_feature(cfeature.STATES.with_scale(res))
# Add the title
tl1 = 'HRRR 2m temperature (°C)'
tl2 = f'Analysis valid at: {hour}00 UTC {date}'
ax.set_title(f'{tl1}\n{tl2}',fontsize=16)
# Contour fill
CF = ax.contourf(x,y,airTemp,levels=fint,cmap=plt.get_cmap('coolwarm'))
# Make a colorbar for the ContourSet returned by the contourf call.
cbar = fig.colorbar(CF,shrink=0.5)
cbar.set_label(f'2m Temperature (°C)', size='large')
Summary
Xarray can read gridded datasets in Zarr format, which is ideal for a cloud-based object store system such as S3.
Xarray and MetPy both support Dask, a library that is particularly well-suited for very large datasets.
What’s next?
On your own, browse the hrrrzarr S3 bucket. Try making maps for different variables and/or different times.