
Dask Overview
In this tutorial, you learn:
What is Dask?
Why Dask in Geosciences?
Dask Data Structures and Schedulers
When to use Dask?
Introduction
Complex data structures enable data science in Python. For example:
But datasets are getting larger all of the time! What if my dataset is too big to fit into memory, or it takes too long to complete an analysis?
What is Dask?
Dask is an open-source Python library for parallel and distributed computing that scales the existing Python ecosystem.
Dask was developed to scale Python packages such as Numpy, Pandas, and Xarray to multi-core machines and distributed clusters when datasets exceed memory.
Why Dask?
Familiar Interface
Dask provides interfaces which mimics significant portions of the NumPy and Pandas APIs.
This means Dask provides ways to parallelize Pandas, Xarray, and Numpy workflows with minimal code rewriting (no massive code-restructure or writing a script in another language).
Scalability
Dask is designed to scale well from single machine (laptop) to thousand-node HPC clusters, and on the cloud.
This allows users to use their existing hardware, or add more machines as needed, to handle increasingly large and complex datasets.
Flexibility
Dask provides several tools that help with data analysis on large datasets. For example, you can easily wrap your function in dask.delayed decorator to make it run in parallel.
Dask provides seamless integration with well-known HPC resource managers and job scheduling systems, including PBS, SLURM, and SGE.
Built-in Diagnostic Tools
Dask provides responsive feedback via the client as well as a real-time interactive diagnostic dashboard to keep users informed on how the computation is progressing.
This helps users identify and resolve potential issues without waiting for the work to be completed.
First Rule of Dask
While Dask is a powerful tool for parallel and distributed computing, it is not always the best solution for every problem. In some cases, using Dask may introduce additional complexity and overhead, without providing any substantial benefits in terms of performance or scalability.
Keep in mind the time spent parallelizing and optimizing your workflow when using Dask vs. the time saved because of that parallelization.
Consider how many times you plan to run your code - if only once, is it worth it?
NOTE: Dask should only be used when necessary.
Avoid Dask if you can easily:
- Speed up your code with use of compiled routines in libraries like NumPy
- Profile and optimize your serial code to minimize bottlenecks
- Read in a subset of data to gain the insight you need

When to use Dask?
Here are some general guidelines for when to use Dask and when to avoid it:
Use Dask:
When you have large datasets that don’t fit into memory on a single machine.
When you need to perform parallel computations, such as big data analysis.
Avoid Dask:
When you have small datasets that can be processed efficiently on a single machine.
When you don’t need parallel processing, as the overhead of managing a distributed computing environment may not be worth the benefits.
When you need to debug or troubleshoot problems, as distributed computing environments can be challenging for debugging. If the problem is complex, using Dask may make debugging more difficult.
Dask Components
Dask is composed of two main parts:
1. Dask Collections
Dask Collections are the user interfaces we use for parallel and distributed computing with Dask.
Dask features different levels of collection types:
High-level collections
Dask provides high-level collections Dask Arrays, Dask DataFrames, and Dask Bags that mimic NumPy, pandas, and lists but can operate in parallel on datasets that don’t fit into memory.
Most of the time, you will probably use one of the following high-level (big) data structures (or an even higher-level derivative type like Xarrays):
Collection |
Serial |
Dask |
|---|---|---|
Arrays |
numpy.array |
dask.array.from_array |
Dataframes |
pandas.read_csv |
dask.dataframe.read_csv |
Unstructured |
[1,2,3] |
dask.bag.from_sequence([1,2,3]) |
Low-level collections
Dask also features two low-level collection types - delayed and futures. These collections give users finer control to build custom parallel and distributed computations.
delayed - run any arbitrary Python function using Dask task parallelism (think looped function calls)
futures - similar to delayed but allows for concurrent commands in the client script (think backgrounded processes)
These are very powerfull tools, but it is easy to write something using a delayed function that could be executed faster and more simply using a high-level collection

Image credit: Dask Contributors
2. Dynamic Task Scheduling
We can basically think of the Dask scheduler as our task orchestrator.
When a computation is submitted, work is segmented into discrete tasks which are assigned to workers by the Dask scheduler.
To perform work, a scheduler must be assigned resources in the form of a Dask cluster. The cluster consists of the following components:
scheduler : A scheduler creates and manages task graphs and distributes tasks to workers.
workers : A worker is typically a separate Python process on either the local host or a remote machine. A Dask cluster usually consists of many workers. Basically, a worker is a Python interpretor which will perform work on a subset of our dataset.
client - A high-level interface that points to the scheduler (often local but not always). A client serves as the entry point for interacting with a Dask scheduler.
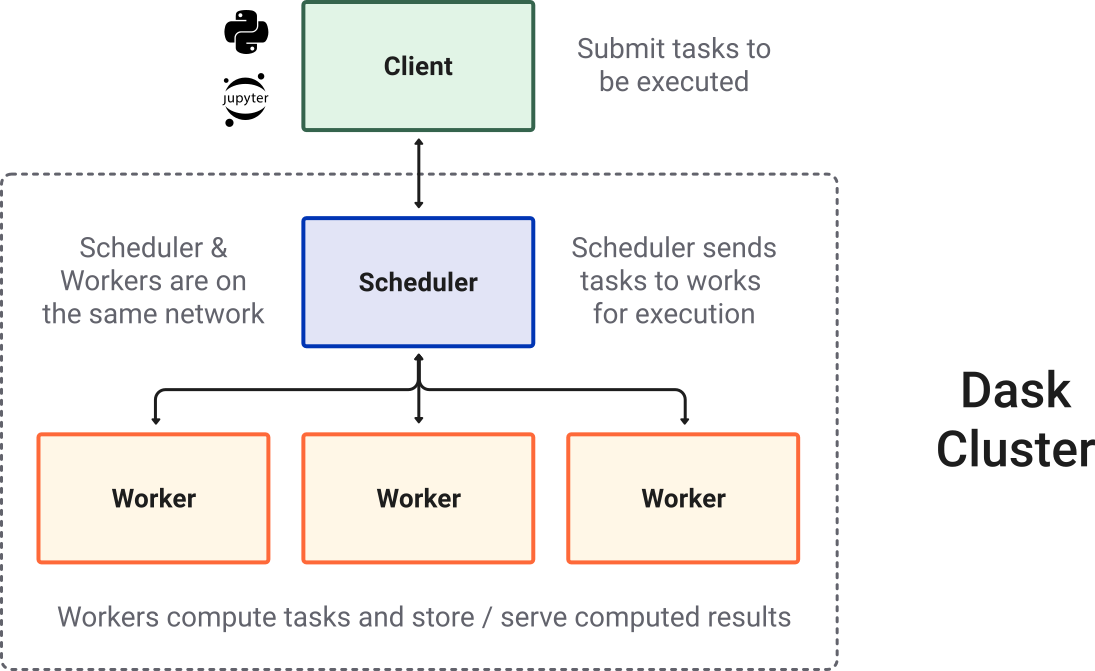
Image credit: Dask Contributors
We will learn more about Dask Collections and Dynamic Task Scheduling in the next tutorials.
Useful Resources
Reference
Ask for help
dasktag on Stack Overflow, for usage questionsgithub issues for bug reports and feature requests
discourse forum for general, non-bug, questions and discussion