
Dask Schedulers
In this tutorial, you learn:
Components of Dask Schedulers
Types of Dask Schedulers
Single Machine Schedulers
Related Documentation
Introduction
As we mentioned in our Dask overview, Dask is composed of two main parts:
Dask Collections (APIs)
Dynamic Task Scheduling
So far, we have talked about different Dask collections, but in this tutorial we are going to talk more about the second part.
The Dask scheduler - our task orchestrator
The Dask.distributed task scheduler is a centralized, dynamic system that coordinates the efforts of various dask worker processes spread accross different machines.
When a computational task is submitted, the Dask distributed scheduler sends it off to a Dask cluster - simply a collection of Dask workers. A worker is typically a separate Python process on either the local host or a remote machine.
To perform work, a scheduler must be assigned resources in the form of a Dask cluster. The cluster consists of the following components:
scheduler : A scheduler creates and manages task graphs and distributes tasks to workers.
workers : A worker is typically a separate Python process on either the local host or a remote machine. A Dask cluster usually consists of many workers. Basically, a worker is a Python interpretor which will perform work on a subset of our dataset.
client - A high-level interface that points to the scheduler (often local but not always). A client serves as the entry point for interacting with a Dask scheduler.
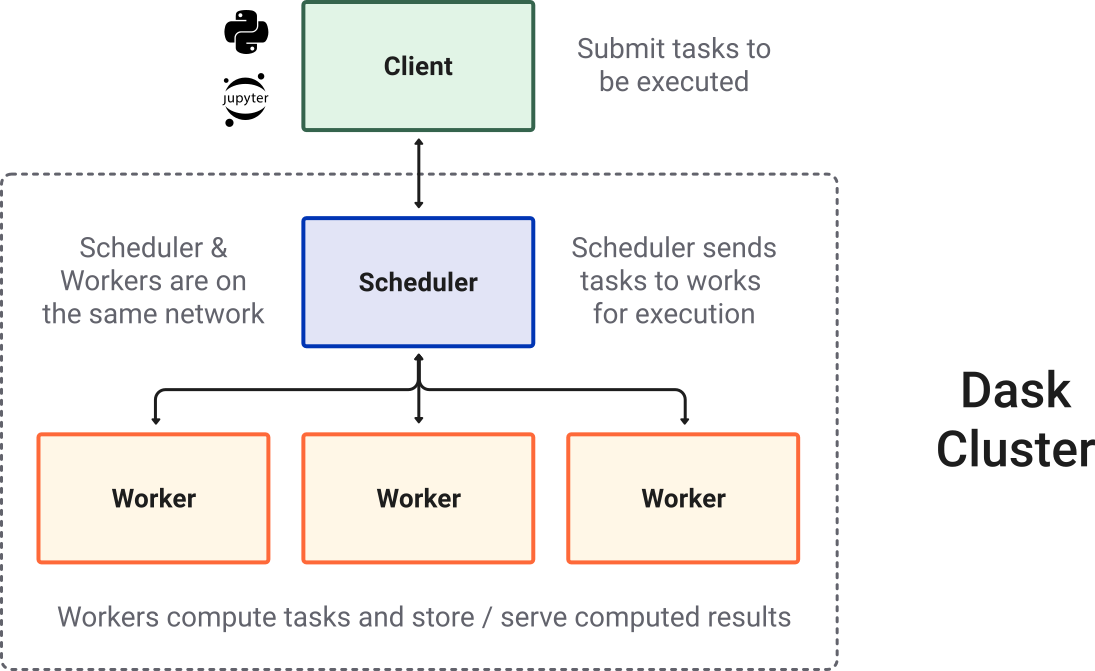
Image credit: Dask Contributors
Schedulers
Dask essentially offers two types of schedulers:

Image credit: Dask Contributors
1. Single machine scheduler
The Single-machine Scheduler schedules tasks and manages the execution of those tasks on the same machine where the scheduler is running.
It is designed to be used in situations where the amount of data or the computational requirements are too large for a single process to handle, but not large enough to warrant the use of a cluster of machines.
It is relatively simple and cheap to use but it does not scale as it only runs on a single machine.
Single machine scheduler is the default choice used by Dask.
In Dask, there are several types of single machine schedulers that can be used to schedule computations on a single machine:
1.1. Single-threaded scheduler
This scheduler runs all tasks serially on a single thread.
This is only useful for debugging and profiling, but does not have any parallelization.
1.2. Threaded scheduler
The threaded scheduler uses a pool of local threads to execute tasks concurrently.
This is the default scheduler for Dask, and is suitable for most use cases on a single machine. Multithreading works well for Dask Array and Dask DataFrame.
To select one of the above scheduler for your computation, you can specify it when doing .compute():
For example:
this.compute(scheduler="single-threaded") # for debugging and profiling only
As mentioned above the threaded scheduler is the default scheduler in Dask. But you can set the default scheduler to Single-threaded or multi-processing by:
import dask
dask.config.set(scheduler='synchronous') # overwrite default with single-threaded scheduler
Multi-processing works well for pure Python code - delayed functions and operations on Dask Bags.
Let’s compare the performance of each of these single-machine schedulers:
import numpy as np
import dask.array as da
%%time
## - numpy performance
xn = np.random.normal(10, 0.1, size=(20_000, 20_000))
yn = xn.mean(axis=0)
yn
CPU times: user 8.47 s, sys: 248 ms, total: 8.72 s
Wall time: 8.71 s
array([ 9.9998496 , 10.00051358, 10.00035799, ..., 10.00021007,
9.99983069, 9.99912034], shape=(20000,))
%%time
# -- dask array using the default
xd = da.random.normal(10, 0.1, size=(20_000, 20_000), chunks=(2000, 2000))
yd = xd.mean(axis=0)
yd.compute()
CPU times: user 13.4 s, sys: 39.9 ms, total: 13.4 s
Wall time: 3.5 s
array([10.00007467, 10.00062536, 9.99928054, ..., 9.99925239,
10.00181827, 9.99819043], shape=(20000,))
import time
# -- dask testing different schedulers:
for sch in ['threading', 'processes', 'sync']:
t0 = time.time()
r = yd.compute(scheduler=sch)
t1 = time.time()
print(f"{sch:>10} : {t1 - t0:0.4f} s")
threading : 3.3384 s
processes : 4.2824 s
sync : 8.5121 s
yd.dask
HighLevelGraph
HighLevelGraph with 4 layers and 240 keys from all layers.
Layer1: normal
normal-9bd7ece2c29f9dcb4d59521e8f4d4036
|
Layer2: mean_chunk
mean_chunk-e5fd434f5060a80324d5190d2a74872b
|
Layer3: mean_combine-partial
mean_combine-partial-dffa84a7962015759ad77258b5aa3c92
|
Layer4: mean_agg-aggregate
mean_agg-aggregate-1949506ceb75e604448a4f4b26c05266
|
yd
|
||||||||||||||||
Notice how
syncscheduler takes almost the same time as pure NumPy code.Why is the multiprocessing scheduler so much slower?
If you use the multiprocessing backend, all communication between processes still needs to pass through the main process because processes are isolated from other processes. This introduces a large overhead.
The Dask developers recommend using the Dask Distributed Scheduler which we will cover now.
2. Distributed scheduler
The Distributed scheduler or
dask.distributedschedules tasks and manages the execution of those tasks on workers from a single or multiple machines.This scheduler is more sophisticated and offers more features including a live diagnostic dashboard which provides live insight on performance and progress of the calculations.
In most cases, dask.distributed is preferred since it is very scalable, and provides and informative interactive dashboard and access to more complex Dask collections such as futures.
2.1. Local Cluster
A Dask Local Cluster refers to a group of worker processes that run on a single machine and are managed by a single Dask scheduler.
This is useful for situations where the computational requirements are not large enough to warrant the use of a full cluster of separate machines. It provides an easy way to run parallel computations on a single machine, without the need for complex cluster management or other infrastructure.
Let’s start by creating a Local Cluster
For this we need to set up a LocalCluster using dask.distributed and connect a client to it.
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
client
Client
Client-7bd12070-d1fb-11ef-8b94-002248917c55
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
ccb867dc
| Dashboard: http://127.0.0.1:8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 15.61 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-a8db8a43-83be-4aa0-8013-471a41d0bdc2
| Comm: tcp://127.0.0.1:41175 | Workers: 4 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 15.61 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:39013 | Total threads: 1 |
| Dashboard: http://127.0.0.1:35693/status | Memory: 3.90 GiB |
| Nanny: tcp://127.0.0.1:36371 | |
| Local directory: /tmp/dask-scratch-space/worker-in8yg1s_ | |
Worker: 1
| Comm: tcp://127.0.0.1:36425 | Total threads: 1 |
| Dashboard: http://127.0.0.1:34853/status | Memory: 3.90 GiB |
| Nanny: tcp://127.0.0.1:45909 | |
| Local directory: /tmp/dask-scratch-space/worker-h8soxh5g | |
Worker: 2
| Comm: tcp://127.0.0.1:32835 | Total threads: 1 |
| Dashboard: http://127.0.0.1:39375/status | Memory: 3.90 GiB |
| Nanny: tcp://127.0.0.1:44945 | |
| Local directory: /tmp/dask-scratch-space/worker-3j5ejpi0 | |
Worker: 3
| Comm: tcp://127.0.0.1:39347 | Total threads: 1 |
| Dashboard: http://127.0.0.1:36995/status | Memory: 3.90 GiB |
| Nanny: tcp://127.0.0.1:40097 | |
| Local directory: /tmp/dask-scratch-space/worker-d1ucffp_ | |
☝️ Click the Dashboard link above.
👈 Or click the “Search” 🔍 button in the dask-labextension dashboard.
If no arguments are specified in LocalCluster it will automatically detect the number of CPU cores your system has and the amount of memory and create workers to appropriately fill that.
A LocalCluster will use the full resources of the current JupyterLab session. For example, if you used BinderHub, it will use the number of CPUs selected.
Note that LocalCluster() takes a lot of optional arguments, allowing you to configure the number of processes/threads, memory limits and other settings.
You can also find your cluster dashboard link using :
cluster.dashboard_link
'http://127.0.0.1:8787/status'
%%time
# -- dask array using the default
xd = da.random.normal(10, 0.1, size=(30_000, 30_000), chunks=(3000, 3000))
yd = xd.mean(axis=0)
yd.compute()
CPU times: user 653 ms, sys: 111 ms, total: 763 ms
Wall time: 9.04 s
array([10.00039405, 10.00083959, 10.0004749 , ..., 9.99955689,
10.00091424, 10.00125579], shape=(30000,))
Always remember to close your local Dask cluster:
client.shutdown()
Dask Distributed (Cluster Managers)
So far we have talked about running a job on a local machine.
Dask can be deployed on distributed infrastructure, such as a an HPC system or a cloud computing system.

Image credit: Dask Contributors
Dask Cluster Managers have different names corresponding to different computing environments. Some examples are dask-jobqueue for your HPC systems (including PBSCluster) or Kubernetes Cluster for machines on the Cloud.
The NCAR tutorial series includes an in-depth exploration and practical use cases of Dask on HPC systems and best practices for Dask on HPC. For the complete set of NCAR tutorial materials, please refer to the main NCAR tutorial content available here.
For more information visit the Dask Docs.