Overview¶
In this cookbook we will go through a simple example showing the Supervised Machine Learning Regression Framework, using the scikit-learn ecosystem.
Reading Data and Exploratory Data Analysis
Splitting Dataset and Scaling Data
Training, Testing, and Validating Model
This is a MVP (or minimum viable product) for ML modeling analysis. There are many more things we could test and add to this. The dataset itself is also very small for fast loading and general speed. This CookBook is meant to be a companion to Unidata’s Cybertraining project.
Prerequisites¶
| Concepts | Importance | Notes |
|---|---|---|
| Machine Learning Foundations in the Earth Systems Sciences | Necessary | |
| 10 minutes to pandas | Necessary | |
| Pyplot tutorial | Helpful | Necessary |
| Numpy: the absolute basics for beginners | Great to have | arrays are the language of machine learning |
Time to learn: 45 minutes
While it can be easy to get started with the scikit learn syntax, it can take a while to fully understand and learn all of the in’s and out’s of ML systems. This is designed to just be a very quick introduction.
Imports¶
Uncomment the below line if you need to install the packages below
# pip install numpy pandas seaborn matplotlib pyarrowimport numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# needed to read in parquet files
import pyarrowWe will do more imports as they come in the notebook.
Read in the data¶
First we will read our data file and examine it’s size. We can also read csv files using the read_csv() function from pandas.
df = pd.read_parquet(r'../0_data/ptype_sampled.parquet')memory_in_megabytes = df.memory_usage(deep=True).sum() / (1024 ** 2)
print(f"The DataFrame size is: {memory_in_megabytes:.2f} MB")
print('The shape of the Dataframe is ' + str(df.shape))The DataFrame size is: 0.06 MB
The shape of the Dataframe is (2000, 6)
So we have 2000 rows, and 6 columns
Let’s examine the columns of our dataframe:
column_names = df.columns.tolist()
print(column_names)['TEMP_C_0_m', 'T_DEWPOINT_C_0_m', 'PRES_Pa_0_m', 'UGRD_m/s_0_m', 'VGRD_m/s_0_m', 'ptype']
These names stand for Temperature and Dewpoint Temperature, (both in degrees Celsius), Atmospheric Pressure in Pascals, U and V components of the Wind in meters per second, and finally, Precipitation Type. All of these variables are measured at ground level.
Let’s do EDA¶
After we have imported our data, the next step is to explore it. This part is called Exploratory Data Analysis (EDA). The describe() function will give us some descriptive statistics about our columns with numeric values.
df.describe()Take a look at the count row, we have 2000 entries in each column, so there is no missing data! Each variable has different means, but some have different standard deviations.
It is easier to see the relationship between our variables if we plot them:
sns.pairplot(df, hue='ptype')<seaborn.axisgrid.PairGrid at 0x7f9539542f90>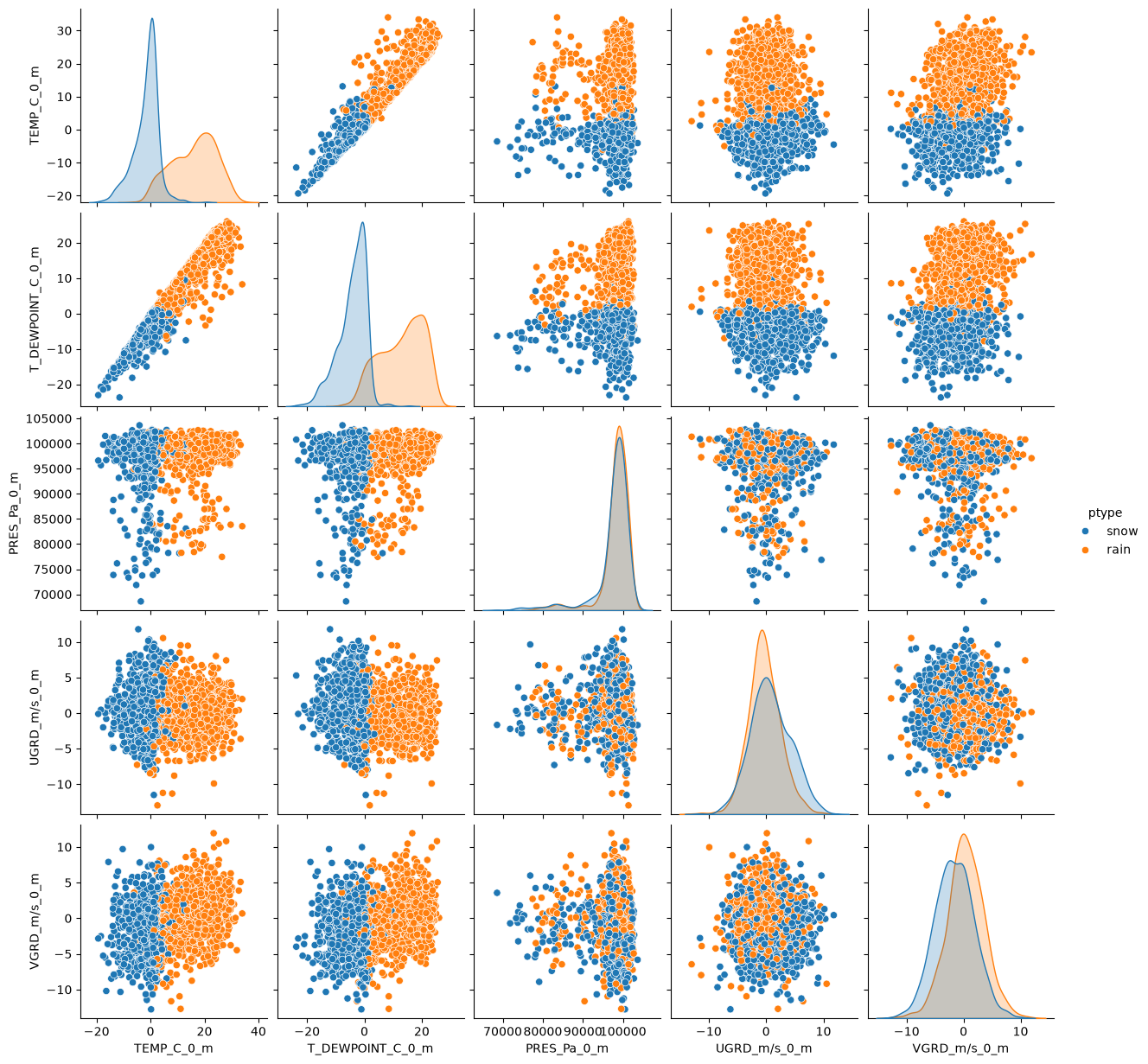
Notice any trends so far? What input features might be the most important?
Next we can plot the Correlation Matrix. As the name suggests, this will show us the correlation between variables. The closer the absolute value is to 1, the stronger the relationship between these variables is. Notice how all of our diagonal values equal to 1? this is because they represent the correlation between a variable and itself. Can you see which other variables have strong correlations?
For further reading, visit Correlation Matrix, Demystified
plt.figure(figsize=(10, 8))
sns.heatmap(df.select_dtypes(include=['number']).corr(), vmin=-1, vmax=1, cmap='coolwarm', annot=True)
plt.title('Correlation Matrix')
plt.show()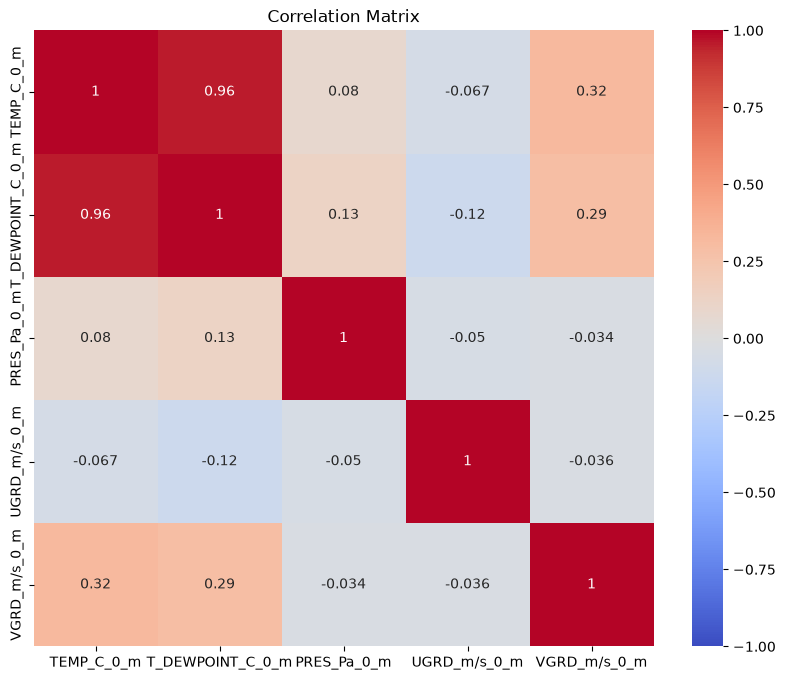
Splitting Datasets¶
In this section we will learn how to split our data into the training, validation, and testing sets. As the name suggests, training set is used to teach the model about the data, while validation and testing sets are used to asses the performance of the model. To learn more about the differences between the three, read the following article: What is the Difference Between Test and Validation Datasets? Or browse through this module to also learn more details about the ML framework: Machine Learning Foundations in the Earth Systems Sciences
from sklearn.model_selection import train_test_splitFor this notebook, we will be doing a regression problem. The ptype variable will just be used for EDA. This example uses Temperaturere, Pressure, and Wind Components (x variables) to determine the dewpoint (y variable).
X = df[['TEMP_C_0_m', 'PRES_Pa_0_m','UGRD_m/s_0_m', 'VGRD_m/s_0_m' ]]
y = df['T_DEWPOINT_C_0_m']# Splitting into training and temporary set (70% training, 30% temporary)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
# Splitting the temporary set into testing and validation sets (20% testing, 10% validation of the original dataset)
X_test, X_val, y_test, y_val = train_test_split(X_temp, y_temp, test_size=1/3, random_state=42)Scaling Your Data¶
After we split the data, we must scale it. Scaling helps us make sure all features, or variables, contribute equally to the model. We will be using scikit-learn’s StandardScaler() function, which standardizes our features by substracting the mean from each observation and then dividing by the standard deviation.
from sklearn.preprocessing import StandardScaler# Initialize the scaler
scaler = StandardScaler()In the following code, the fit_transform() function calculates the mean and standard deviation (fit) of X_train, and then uses those parameters to scale the data (transform).
# Fit the scaler to the training data and transform it
X_train_scaled = scaler.fit_transform(X_train)
# Transform the testing and validation data using the same scaler
X_test_scaled = scaler.transform(X_test)
X_val_scaled = scaler.transform(X_val)Notice how we are using transform() on our testing and validation data instead. This allows us to use the same mean and invariance as in the training set and keep the testing/validation data “unseen”. This last part is especially important to maintain an unbiased model.
The following article provides a more detailed explanation: What and why behind fit_transform() and transform() in scikit-learn!
Note
Always scale datasets after splitting to prevent data leakage!Machine Learning¶
Training¶
We will use a linear regression model:
from sklearn.linear_model import LinearRegression# Initialize the Logistic Regression model
model = LinearRegression()# Train the model with the training data
model.fit(X_train_scaled, y_train)Next step, let’s use the testing data and plot the new predicted values vs true values.
# Predicting the Test set results
y_pred = model.predict(X_test_scaled)# Create scatter plot
plt.scatter(y_test, y_pred, alpha=0.2)
# Add axis labels
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
# Set the same limits for both axes
min_val = min(min(y_test), min(y_pred))
max_val = max(max(y_test), max(y_pred))
plt.xlim(min_val, max_val)
plt.ylim(min_val, max_val)
# Add a diagonal line for reference
plt.plot([min_val, max_val], [min_val, max_val], 'r--')
# Show the plot
plt.show()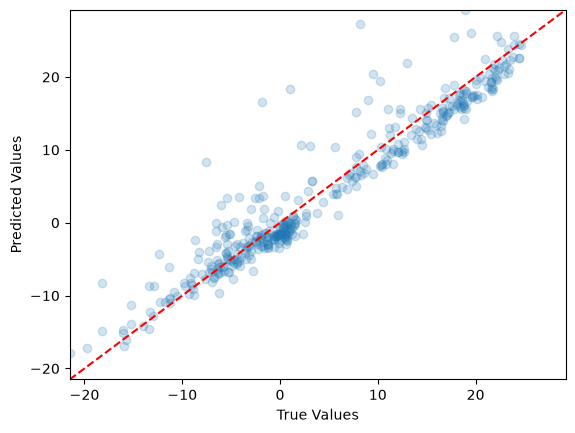
Regression Metrics¶
from sklearn.metrics import root_mean_squared_error, r2_score
# Calculate RMSE & R2
rmse = root_mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"RMSE on Test Set: {rmse:.2f}")
print(f"R-squared (R2) on Test Set: {r2:.2f}")RMSE on Test Set: 3.23
R-squared (R2) on Test Set: 0.91
R-squared (R²) and Root Mean Squared Error (RMSE) are both metrics used to evaluate the performance of regression models, but they convey different types of information.
R², also known as the coefficient of determination, measures the proportion of the variance in the dependent variable that is predictable from the independent variables. It ranges from 0 to 1, where a higher value indicates a better fit of the model to the data, with 1 representing a perfect fit.
RMSE, on the other hand, quantifies the average magnitude of the prediction errors, providing an absolute measure of fit in the same units as the dependent variable. It calculates the square root of the average squared differences between predicted and observed values, with a lower RMSE indicating a model that predicts more accurately. While R² gives a sense of how well the model explains the variability of the data, RMSE provides a direct measure of the model’s prediction accuracy.
This blog post covers some of the downsides to looking at R2 alone.
Now let’s try it on the validation set¶
At this point we could make some changes to our model based on the metrics we got after testing and repeat the training and testing process. Once we are done we can proceed to validate model:
# Predicting the Validation set results
y_val_pred = model.predict(X_val_scaled)
# Calculate RMSE & R2
rmse_val = root_mean_squared_error(y_val, y_val_pred)
r2_val = r2_score(y_val, y_val_pred)
print(f"RMSE on Validation Set: {rmse_val:.2f}")
print(f"R-squared (R2) on Validation Set: {r2_val:.2f}")RMSE on Validation Set: 2.36
R-squared (R2) on Validation Set: 0.95
Different dataset, different results?¶
Let’s look at another dataset. This dataset just has snow and freezing rain as the p-types, so overall it will be colder. Let’s see if we get similar results.
df_frza = pd.read_parquet(r'../0_data/ptype_sampled_frza.parquet')df_frza.describe()sns.pairplot(df_frza, hue='ptype')<seaborn.axisgrid.PairGrid at 0x7f94d2c4a710>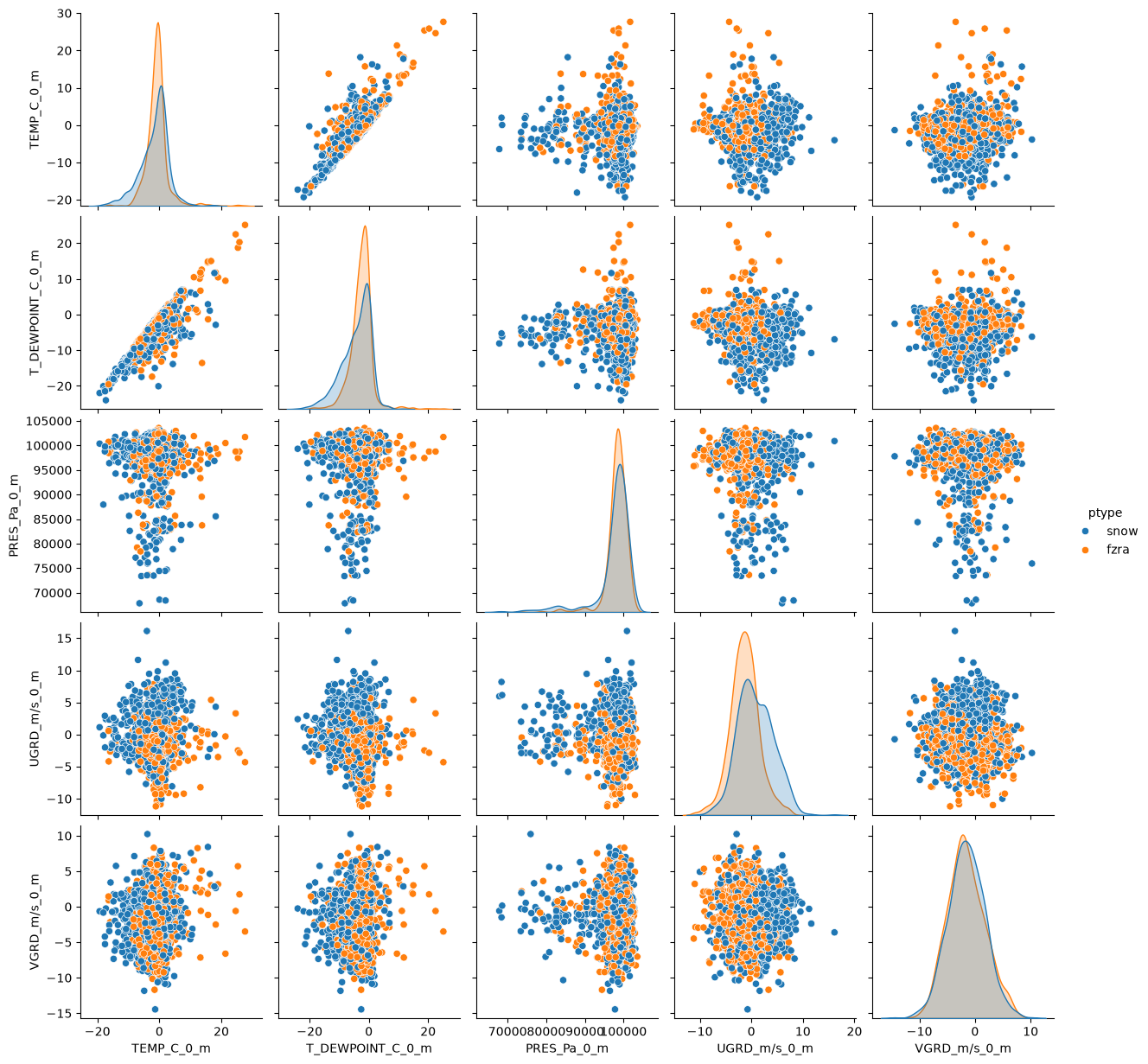
plt.figure(figsize=(10, 8))
sns.heatmap(df_frza.select_dtypes(include=['number']).corr(), vmin=-1, vmax=1, cmap='coolwarm', annot=True)
plt.title('Correlation Matrix')
plt.show()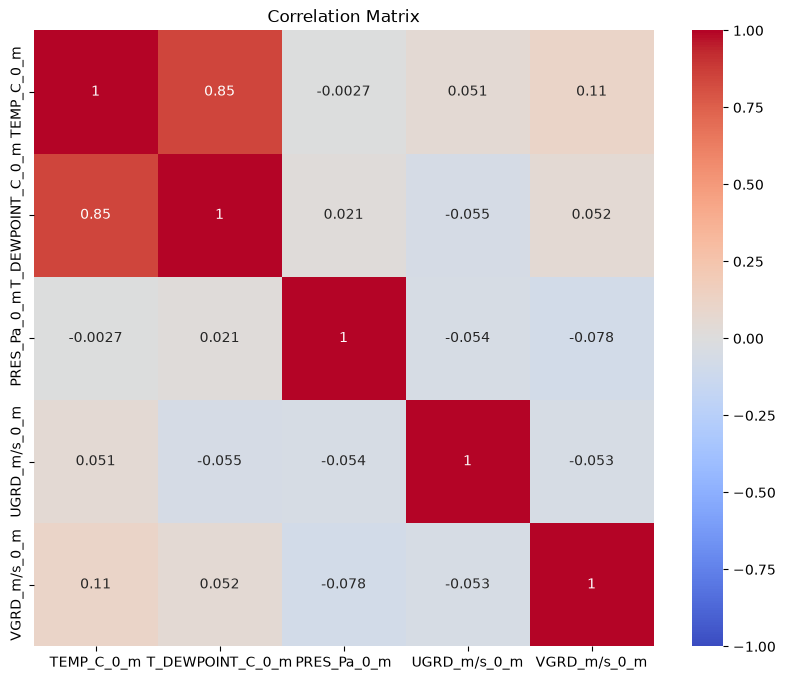
What are the differences in EDA compared to rain vs snow? Do you expect this to do better or worse compared to rain vs snow?
Split up the data & Scale¶
The following code is a bit compressed, but is the same line for line as above, just with a new dataset.
X2 = df_frza[['TEMP_C_0_m', 'PRES_Pa_0_m','UGRD_m/s_0_m', 'VGRD_m/s_0_m' ]]
y2 = df_frza['T_DEWPOINT_C_0_m']# Splitting into training and temporary set (70% training, 30% temporary)
X_train2, X_temp2, y_train2, y_temp2 = train_test_split(X2, y2, test_size=0.3, random_state=42)
# Splitting the temporary set into testing and validation sets (20% testing, 10% validation of the original dataset)
X_test2, X_val2, y_test2, y_val2 = train_test_split(X_temp2, y_temp2, test_size=1/3, random_state=42)# Initialize the scaler
scaler = StandardScaler()# Fit the scaler to the training data and transform it
X_train_scaled2 = scaler.fit_transform(X_train2)
# Transform the testing and validation data using the same scaler
X_test_scaled2 = scaler.transform(X_test2)
X_val_scaled2 = scaler.transform(X_val2)Notice the new model! We will be using a Decision Tree. If you want to learn more, here is a StatQuest video.
# Decision Tree Regressor
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()# Train the model with the training data
model.fit(X_train_scaled2, y_train2)Test Set ML¶
# Predicting the Test set results
y_pred2 = model.predict(X_test_scaled2)rmse = root_mean_squared_error(y_test2, y_pred2)
r2 = r2_score(y_test2, y_pred2)
print(f"RMSE on Test Set: {rmse:.2f}")
print(f"R-squared (R2) on Test Set: {r2:.2f}")RMSE on Test Set: 2.80
R-squared (R2) on Test Set: 0.58
# Create scatter plot
plt.scatter(y_test2, y_pred2, alpha=0.2)
# Add axis labels
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
# Set the same limits for both axes
min_val = min(min(y_test2), min(y_pred2))
max_val = max(max(y_test2), max(y_pred2))
plt.xlim(min_val, max_val)
plt.ylim(min_val, max_val)
# Add a diagonal line for reference
plt.plot([min_val, max_val], [min_val, max_val], 'r--')
# Show the plot
plt.show()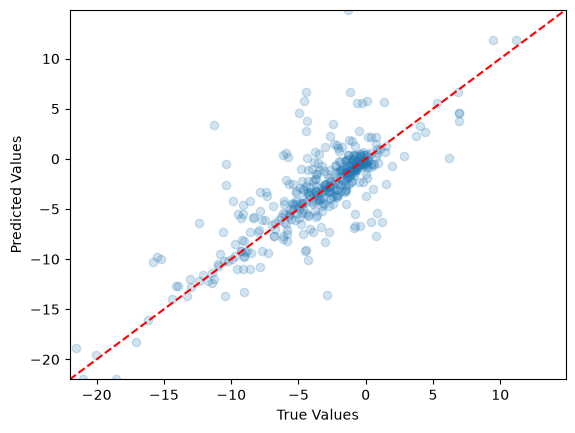
What do you notice in this scatter plot compared to the one with rain vs snow?
Validation Set ML¶
# Predicting the Validation set results
y_val_pred2 = model.predict(X_val_scaled2)
# Calculate RMSE & R2
rmse_val = root_mean_squared_error(y_val2, y_val_pred2)
r2_val = r2_score(y_val2, y_val_pred2)
print(f"RMSE on Validation Set: {rmse_val:.2f}")
print(f"R-squared (R2) on Validation Set: {r2_val:.2f}")RMSE on Validation Set: 2.72
R-squared (R2) on Validation Set: 0.66
More Questions¶
What do you see comparing the metrics; freezing rain vs snow and snow vs rain? Is this what you expected?
Is the Decision Tree model consistent between testing and validations sets for both experiments? Could we potentially use a more complex model?
How many lines of code does it take to do a quick ML analysis with a testing, training, and validation dataset?
Summary¶
In this notebook we learned:
What Exploratory Data Analysis is and some useful functions that can help you in the process of understading your data.
How and why we split and scale data
How to train your model and evaluate its accuracy afterwards
What’s next?¶
Let Jupyter book tie this to the next (sequential) piece of content that people could move on to down below and in the sidebar. However, if this page uniquely enables your reader to tackle other nonsequential concepts throughout this book, or even external content, link to it here!