
Formato Zarr para Datos Científicos¶
📚 Descripción general¶
En este cuadernillo aprenderás todo sobre Zarr, el formato ARCO más usado para datos científicos multidimensionales:
¿Qué es Zarr? - Conceptos fundamentales (Store, Group, Array)
Exportar a Zarr - Convertir datos radar a formato Zarr
Carga perezosa - Trabajar con archivos sin cargarlos en memoria
Fragmentación - Optimizar rendimiento según tu caso de uso
Metadatos - Inspeccionar estructura interna de archivos Zarr
Trabajarás con datos reales de radar meteorológico colombiano.
✅ Requisitos previos¶
| Concepto | Importancia | Notas |
|---|---|---|
| Introducción a ARCO | Necesario | Conceptos ARCO y FAIR |
| Introducción a Radar | Necesario | Datos radar meteorológico |
| Xarray | Necesario | Manipulación de datos multidimensionales |
⏱️ Tiempo estimado de aprendizaje:
📖 Solo lectura: 15–20 minutos
🏋️ Con actividades prácticas: 25–30 minutos
✍️ Formato: práctico, ejecuta y modifica el código
Librerías¶
Importamos las librerías necesarias para este cuaderno.
import xarray as xr # Estructuras de datos multidimensionales
import xradar as xd # Lectura y manipulación de datos radar
import zarr # Formato de almacenamiento optimizado
import numpy as np # Operaciones numéricas
import matplotlib.pyplot as plt # Visualización
import cmweather # Colormaps meteorológicos
import os # Operaciones del sistema de archivos
from pathlib import Path # Manejo de rutas1. ¿Qué es Zarr?¶
Zarr es un formato para almacenar grandes arrays N-dimensionales — en fragmentos (chunks) — con metadatos, diseñado para acceso rápido y paralelo desde almacenamiento local o en la nube.
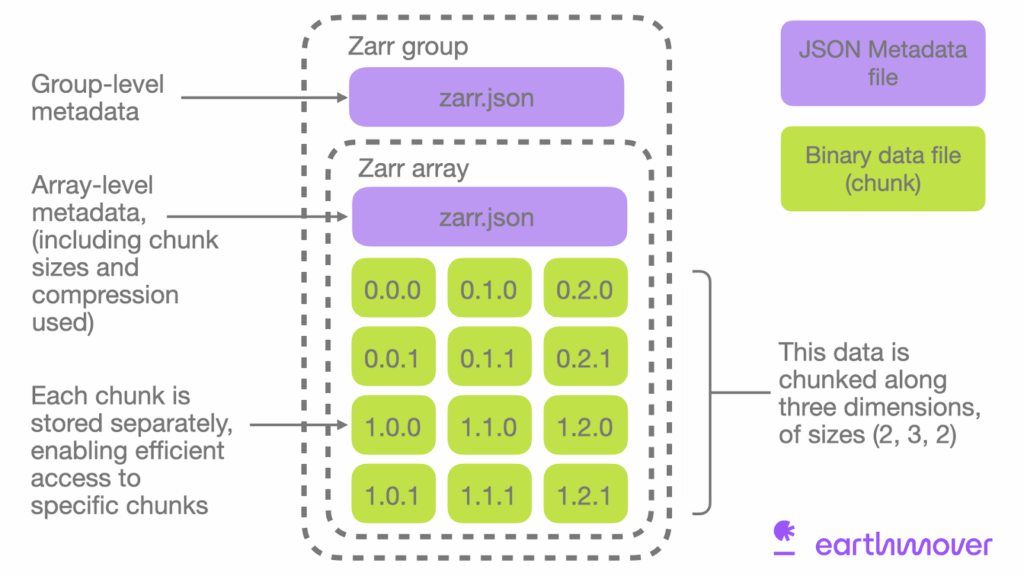
Figure 1:Conceptos clave de Zarr: Store y Group. Imagen cortesía: Earthmover
Conceptos clave de Zarr:¶
Store (Almacén):
Un directorio en disco (e.g.,
LocalStore)Un bucket en la nube (e.g.,
FsspecStorepara s3://…)En memoria (e.g.,
MemoryStore)
Group (Grupo):
Un grupo puede contener múltiples arrays Zarr relacionados
Puede contener otros grupos (jerarquía anidada)
Cada grupo tiene sus propios metadatos (en
zarr.json)
Ventajas de Zarr:¶
📦 Compresión - Para ahorrar espacio de almacenamiento
🔀 Acceso paralelo - Por múltiples usuarios simultáneamente
📡 Transmisión eficiente - Desde almacenamiento en nube
⚡ Procesamiento bajo demanda - Sin necesidad de descargar todo
Piensa en ello como tener una biblioteca donde puedes tomar solo los libros que necesitas, ¡en lugar de tener que llevarte toda la biblioteca!
Características clave de Zarr¶
Formato abierto y libre - No propietario, código abierto
Compatible con NumPy - Se integra perfectamente con el ecosistema científico de Python
Compresión flexible - Múltiples algoritmos de compresión disponibles
Metadatos integrados - Autodescriptivo, similar a NetCDF
Almacenamiento jerárquico - Soporta estructuras de grupos anidados
Optimizado para nube - Diseñado desde el inicio para object storage (S3, GCS, Azure)
Zarr vs NetCDF: Comparación¶
| Característica | NetCDF | Zarr |
|---|---|---|
| Fragmentación | Limitada | Flexible y optimizada |
| Acceso paralelo | Difícil | Nativo |
| Almacenamiento nube | Ineficiente | Optimizado |
| Compresión | Limitada | Múltiples opciones |
| Escritura concurrente | No | Sí |
| Tamaño máximo | Limitado por formato | Sin límite práctico |
| Madurez | Muy maduro | En crecimiento rápido |
2. Exportar Datos a Zarr¶
Ahora que entiendes qué es Zarr, ¡veámoslo en acción! Vamos a:
Cargar datos radar del cuadernillo anterior (1.5)
Exportarlos al formato Zarr
Examinar la estructura del archivo Zarr resultante
# Cargar datos radar usando xradar (del cuadernillo 1.5)
archivo_radar = "../data/CAR220809191504.RAWDSX2"%%time
radar_dt = xd.io.open_iris_datatree(archivo_radar)CPU times: user 1.55 s, sys: 48.6 ms, total: 1.6 s
Wall time: 5.67 s
print("Datos radar cargados:")
radar_dtDatos radar cargados:
# Exportar a Zarr
# Especificamos zarr_version=2 para compatibilidad amplia
zarr_path = "../data/radar_carimagua.zarr"
# Eliminar si existe para evitar errores
import shutil
if os.path.exists(zarr_path):
shutil.rmtree(zarr_path)
# Exportar el DataTree completo
radar_dt.to_zarr(zarr_path, mode="w", zarr_version=2, consolidated=True)
print(f"✅ Datos exportados a: {zarr_path}")/tmp/ipykernel_4263/551436027.py:11: FutureWarning: zarr_version is deprecated, use zarr_format
radar_dt.to_zarr(zarr_path, mode="w", zarr_version=2, consolidated=True)
/home/runner/micromamba/envs/cdh-python/lib/python3.13/site-packages/xradar/io/backends/iris.py:249: RuntimeWarning: invalid value encountered in sqrt
return np.sqrt(decode_array(data, **kwargs))
✅ Datos exportados a: ../data/radar_carimagua.zarr
# Examinar estructura del archivo Zarr
# Zarr almacena datos en una estructura de directorio
print("Estructura del archivo Zarr:")
print("\nPrimeros 20 archivos/directorios:")
for i, (root, dirs, files) in enumerate(os.walk(zarr_path)):
if i > 5: # Limitar salida
break
level = root.replace(zarr_path, '').count(os.sep)
indent = ' ' * 2 * level
print(f"{indent}{os.path.basename(root)}/")
subindent = ' ' * 2 * (level + 1)
for file in files[:5]: # Mostrar solo primeros 5 archivos por directorio
print(f"{subindent}{file}")Estructura del archivo Zarr:
Primeros 20 archivos/directorios:
radar_carimagua.zarr/
.zattrs
.zmetadata
.zgroup
sweep_0/
.zattrs
.zgroup
sweep_fixed_angle/
.zattrs
.zarray
0
elevation/
.zattrs
.zarray
0
prt_mode/
.zattrs
.zarray
0
WRADH/
1.0
1.1
.zattrs
3.1
0.1
3. Carga Perezosa (Lazy Loading)¶
Una de las ventajas más poderosas de Zarr es la carga perezosa (lazy loading). Esto significa que podemos abrir un archivo Zarr gigante sin cargar todos los datos en memoria. Solo se cargan los datos cuando realmente los necesitamos.
%%time
radar_zarr = xr.open_datatree( # Abrir archivo Zarr
zarr_path,
engine="zarr",
chunks={},
consolidated=True
)CPU times: user 59.9 ms, sys: 7.09 ms, total: 67 ms
Wall time: 111 ms
# Esto NO carga los datos en memoria, solo los metadatos
print("Archivo Zarr abierto:")
radar_zarrArchivo Zarr abierto:
# Cargar solo un subconjunto de datos
subset = radar_zarr["sweep_0"]
subset # Acceder a una variable específica
# Los datos aún no se cargan en memoria - están "lazy"
dbzh = radar_zarr["sweep_0"]["DBZH"]
print("Variable DBZH (lazy):")
dbzhVariable DBZH (lazy):
# Visualizar el subconjunto
dbzh.plot(cmap="ChaseSpectral", vmin=-10, vmax=60)
plt.title("Reflectividad - Primeros 100 km, 0-180° azimuth")
plt.show()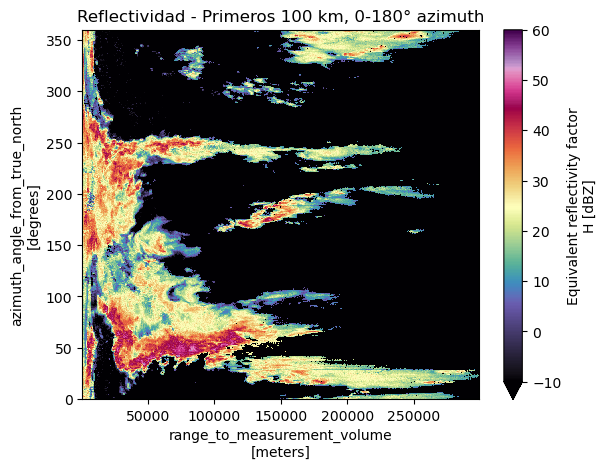
4. Actividades Prácticas¶
Ahora es tu turno de experimentar con Zarr. Estas actividades te ayudarán a dominar fragmentación, rendimiento y metadatos.
🏋️ Práctica 1: Exportar con fragmentación personalizada¶
Zarr permite especificar cómo se fragmentan (chunk) los datos. Una fragmentación óptima puede mejorar significativamente el rendimiento.
Contexto sobre fragmentación:
La fragmentación determina qué tamaño tienen los “bloques” de datos. Opciones comunes:
📏 Estrategias de fragmentación:
{azimuth: 180, range: 250}→ Fragmentos de tamaño específico (bueno para acceso parcial){azimuth: -1, range: -1}→ Un solo fragmento por dimensión (bueno para cargar dimensiones completas)¿Qué significa
-1? → Toda la dimensión en un solo chunk (sin fragmentación adicional)
{azimuth: 360, range: 497}→ Fragmentos medianos (balance entre los dos anteriores)
Tareas:
Carga el dataset de radar nuevamente
Accede al sweep_0 como Dataset
Aplica fragmentación personalizada usando
.chunk()con{azimuth: 180, range: 250}Exporta a Zarr con el nombre
radar_chunked.zarrCompara el tamaño con la versión anterior
Reflexión: ¿En qué caso de uso sería mejor cada estrategia de fragmentación?
# Tu código aquíSolución
# 1. Cargar datos
radar_dt = xd.io.open_iris_datatree("../data/CAR220809191504.RAWDSX2")
# 2. Acceder a sweep_0
sweep0 = radar_dt["sweep_0"].ds
# 3. Aplicar fragmentación personalizada
sweep0_chunked = sweep0.chunk({"azimuth": -1, "range": -1})
# 4. Exportar
zarr_chunked_path = "../data/radar_chunked.zarr"
if os.path.exists(zarr_chunked_path):
shutil.rmtree(zarr_chunked_path)
sweep0_chunked.to_zarr(zarr_chunked_path, mode="w")
# 5. Ver el nuevo esquema de partición o chunking
sweep0_back = xr.open_zarr(zarr_chunked_path, chunks={})
sweep0_back["DBZH"]🏋️ Práctica 2: Comparar velocidad de acceso¶
Compara la velocidad de lectura entre el formato original y Zarr.
Tareas:
Usa
%%timepara medir el tiempo de carga del archivo originalUsa
%%timepara medir el tiempo de apertura del archivo Zarr (lazy)Mide el tiempo de cargar un subconjunto desde Zarr
Explica las diferencias de rendimiento
# Tu código aquíSolución
# 1. Tiempo de carga del formato original
print("=== Formato original RAWDSX2 ===")
%time radar_orig = xd.io.open_iris_datatree("../data/CAR220809191504.RAWDSX2")
# 2. Tiempo de apertura Zarr (lazy)
print("\n=== Zarr (lazy loading) ===")
%time radar_z = xr.open_datatree(zarr_path,engine="zarr")
# 3. Tiempo de cargar subconjunto desde Zarr
print("\n=== Cargar subconjunto desde Zarr ===")
%time subset = radar_z = xr.open_datatree(zarr_path, engine="zarr", group="sweep_0")
print("\n📊 Interpretación:")
print("- RAWDSX2: Carga completa necesaria")
print("- Zarr lazy: Apertura casi instantánea (solo metadatos)")
print("- Zarr subset: Solo carga los fragmentos necesarios")
print("\n✅ Ventaja: Zarr permite exploración rápida y acceso selectivo")🏋️ Práctica 3: Inspeccionar metadatos Zarr¶
Contexto:
Zarr almacena metadatos en archivos JSON legibles por humanos. Esto te permite:
✅ Verificar la compresión aplicada sin cargar datos
✅ Confirmar el tamaño de fragmentos (chunks)
✅ Entender el esquema de datos antes de procesarlos
✅ Diagnosticar problemas de rendimiento
Los archivos clave son:
.zattrs: Atributos del grupo (metadatos personalizados).zarray: Metadata del array (forma, tipo, compresión, chunks).zgroup: Indica que es un grupo Zarr
Exploraremos estos archivos para entender cómo Zarr organiza la información.
Tareas:
Lee el archivo
.zattrsdel grupo raíz de tu archivo ZarrLee el archivo
.zarrayde la variable DBZHIdentifica en el
.zarray: tipo de compresión, forma del array, fragmentación, tipo de datosExplica qué significa cada campo y cómo afecta el rendimiento
# Tu código aquíSolución
import json
# 1. Leer atributos del grupo raíz
print("=== Atributos del grupo raíz (.zattrs) ===")
with open(f"{zarr_path}/sweep_0/.zattrs", 'r') as f:
root_attrs = json.load(f)
print(json.dumps(root_attrs, indent=2)[:500]) # Primeros 500 caracteres
# 2. Leer metadata del array DBZH
print("\n=== Metadata del array DBZH (.zarray) ===")
with open(f"{zarr_path}/sweep_0/DBZH/.zarray", 'r') as f:
dbzh_meta = json.load(f)
print(json.dumps(dbzh_meta, indent=2))
# 3 y 4. Identificar y explicar campos
print("\n📋 Explicación de campos clave:")
print(f"- shape: {dbzh_meta['shape']} → Forma del array (azimuth, range)")
print(f"- chunks: {dbzh_meta['chunks']} → Tamaño de cada fragmento")
print(f"- dtype: {dbzh_meta['dtype']} → Tipo de datos (float32)")
print(f"- compressor: {dbzh_meta['compressor']['id']} → Algoritmo de compresión")
print(f"- order: {dbzh_meta['order']} → Orden de memoria (C=row-major)")
print(f"- fill_value: {dbzh_meta['fill_value']} → Valor para datos faltantes")Resumen¶
En este cuadernillo dominaste el formato Zarr:
✅ Conceptos fundamentales: Store, Group, Array, fragmentación
✅ Exportación: Convertiste datos radar a formato Zarr cloud-optimized
✅ Carga perezosa: Abriste archivos grandes sin cargar todo en memoria
✅ Fragmentación: Optimizaste estrategias de chunking
✅ Metadatos: Inspeccionaste estructura interna JSON
✅ Rendimiento: Comparaste velocidad con formatos tradicionales
Ahora puedes trabajar eficientemente con grandes volúmenes de datos científicos usando formatos ARCO.
💡 ¿Cuándo usar Zarr vs NetCDF?¶
Usa Zarr cuando:
📈 Datasets muy grandes (> 1 GB)
☁️ Almacenamiento en nube (S3, GCS, Azure)
🔀 Acceso paralelo por múltiples usuarios
⚡ Acceso rápido a subconjuntos
📊 Pipelines de análisis escalables
Usa NetCDF cuando:
💾 Sistemas de archivos locales
📁 Datasets pequeños (< 1 GB)
🔒 Compatibilidad con software legacy
📜 Estándares CF requeridos
¿Qué sigue?¶
Ahora que dominas los formatos de datos científicos (NetCDF, GRIB, Zarr), estás listo para aplicar estos conocimientos en el acceso y análisis de datos hidrometeorológicos reales.
Temas avanzados para explorar:¶
Kerchunk: Virtualización de NetCDF como Zarr sin conversión
Dask: Procesamiento paralelo y distribuido
Intake: Catálogos de datos ARCO
Pangeo: Ecosistema de análisis científico en la nube
Recursos recomendados:¶
👉 Continúa con: Sección 2 - Acceso a datos hidrometeorológicos
📚 Referencias¶
Miles, A. et al. (2022). Zarr: A format for the storage of chunked, compressed, N-dimensional arrays. https://zarr.dev
Abernathey, R. et al. (2021). Cloud-Native Repositories for Big Scientific Data. Computing in Science & Engineering, 23(2), 26-35.
WMO (2021). Manual on the WMO Integrated Global Observing System (WIGOS). WMO-No. 1160.
Helmus, J. J., & Collis, S. M. (2016). The Python ARM Radar Toolkit (Py-ART). Journal of Open Research Software, 4(1).