
Introducción a ARCO: Datos Listos para Análisis¶
📚 Descripción general¶
En este cuadernillo aprenderás sobre ARCO (Analysis-Ready Cloud-Optimized), un paradigma moderno para almacenar y acceder datos científicos:
Datos listos para análisis - Por qué importa tener datos preprocesados
Formatos optimizados para la nube - Acceso eficiente a grandes volúmenes
Principios FAIR - Datos científicos reutilizables y citables
Panorama de formatos ARCO - Zarr, Parquet, y otros
Este cuadernillo es conceptual. En el siguiente (1.8) aprenderás Zarr en detalle con ejemplos prácticos.
✅ Requisitos previos¶
| Concepto | Importancia | Notas |
|---|---|---|
| NumPy | Necesario | Arrays multidimensionales |
| Xarray | Necesario | Datos etiquetados |
| NetCDF/GRIB | Útil | Formatos tradicionales |
⏱️ Tiempo estimado de aprendizaje:
📖 Lectura: 20–25 minutos
✍️ Formato: conceptual
1. Datos Listos para Análisis (Analysis-Ready Data)¶
¿Qué significa “Listo para Análisis”?¶
Los datos listos para análisis son conjuntos de datos que han sido preparados y estructurados para ser utilizables inmediatamente en análisis científico. Estudios demuestran que los científicos de datos típicamente dedican ~80% de su tiempo preparando y limpiando datos en lugar de hacer análisis real.
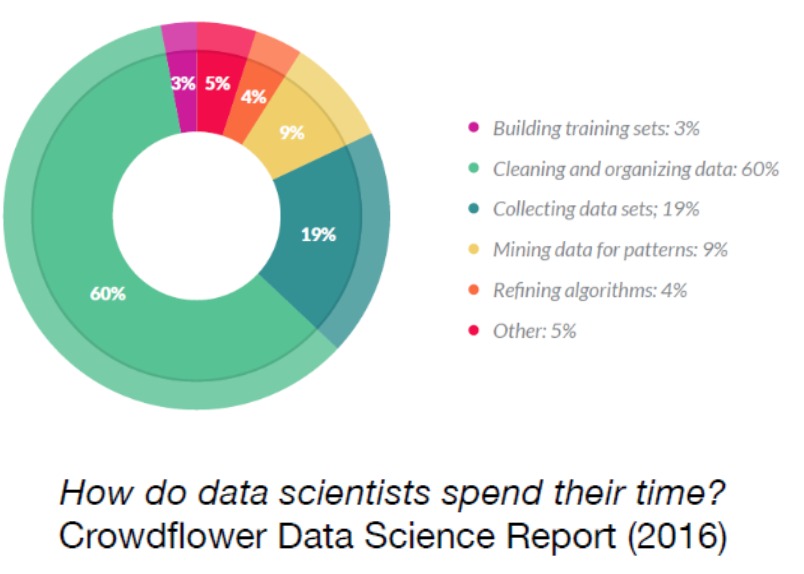
Los datos listos para análisis resuelven esto proporcionando:
✅ Datos limpios y preprocesados - Listos para usar sin necesidad de limpieza adicional
✅ Metadatos ricos - Documentación clara sobre qué contienen los datos
✅ Formatos estandarizados - Compatibles con herramientas de análisis modernas
✅ Control de calidad - Garantía de confiabilidad de los datos
¡Esto significa más tiempo para ciencia y hacer descubrimientos! 🚀
Beneficios clave de los datos listos para análisis¶
| Aspecto | Datos tradicionales | Datos listos para análisis |
|---|---|---|
| Organización | Archivos dispersos | Conjuntos de datos estructurados |
| Limpieza | Requiere horas de preprocesamiento | Pre-procesados y limpios |
| Metadatos | Escasos o ausentes | Ricos e incluidos |
| Descubrimiento | Difícil de encontrar | Catalogados y encontrables |
| Uso inmediato | No | Sí - análisis inmediato |
| Tiempo para ciencia | 20% | 80% |
🤔 Pregunta rápida
Si pasas 8 horas analizando datos, ¿cuánto tiempo dedicas típicamente a limpieza según estudios?
Respuesta: ~6.4 horas (80% del tiempo). ¡Por eso los datos listos para análisis son tan valiosos!
2. Formatos Optimizados para la Nube (Cloud-Optimized)¶
Los formatos tradicionales de datos radar (como archivos NetCDF individuales) funcionan bien en computadoras locales pero son lentos e ineficientes en entornos en la nube. Los formatos optimizados para la nube como Zarr están diseñados específicamente para acceso rápido y eficiente desde almacenamiento en nube.
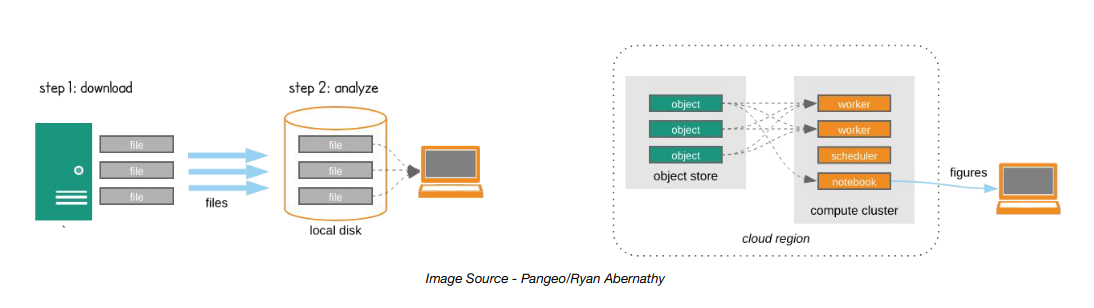
Figure 2:Cortesía: Closed Platforms vs. Open Architectures for Cloud-Native Earth System Analytics
¿Por qué importa la optimización para nube?¶
🚀 Acceso paralelo - Múltiples usuarios pueden leer diferentes partes simultáneamente
📦 Almacenamiento fragmentado - Solo descarga los datos que necesitas
⚡ Transmisión rápida - No necesitas descargar archivos completos
📈 Procesamiento escalable - Maneja conjuntos de datos demasiado grandes para computadoras locales
Comparación: Almacenamiento Monolítico vs Fragmentado¶
Figure 3:Datos Monolíticos Vs Fragmentados. Imagen cortesía: Zarr illustrations
Almacenamiento Monolítico (NetCDF tradicional):
Un solo archivo grande
Debes descargar todo el archivo para acceder a cualquier parte
Lento para acceso remoto
Almacenamiento Fragmentado (Zarr):
Datos divididos en fragmentos pequeños (chunks)
Acceso selectivo - solo descargas lo que necesitas
Rápido para acceso remoto y paralelo
3. Principios FAIR¶
Los datos FAIR siguen principios que hacen que los datos científicos sean más valiosos y reutilizables:
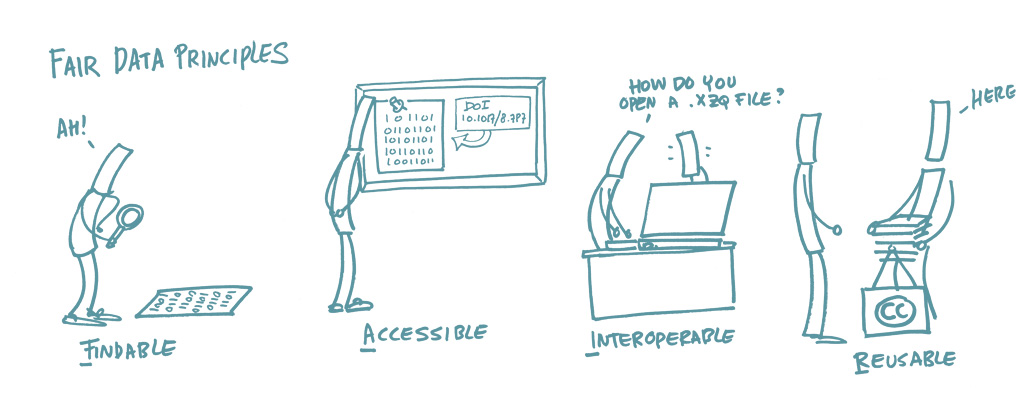
Findable (Encontrable) - Fácil de descubrir mediante catálogos y búsquedas
Accessible (Accesible) - Disponible a través de protocolos estándar
Interoperable (Interoperable) - Funciona con diferentes herramientas y sistemas
Reusable (Reutilizable) - Bien documentado para uso futuro por otros
Beneficios de los datos FAIR¶
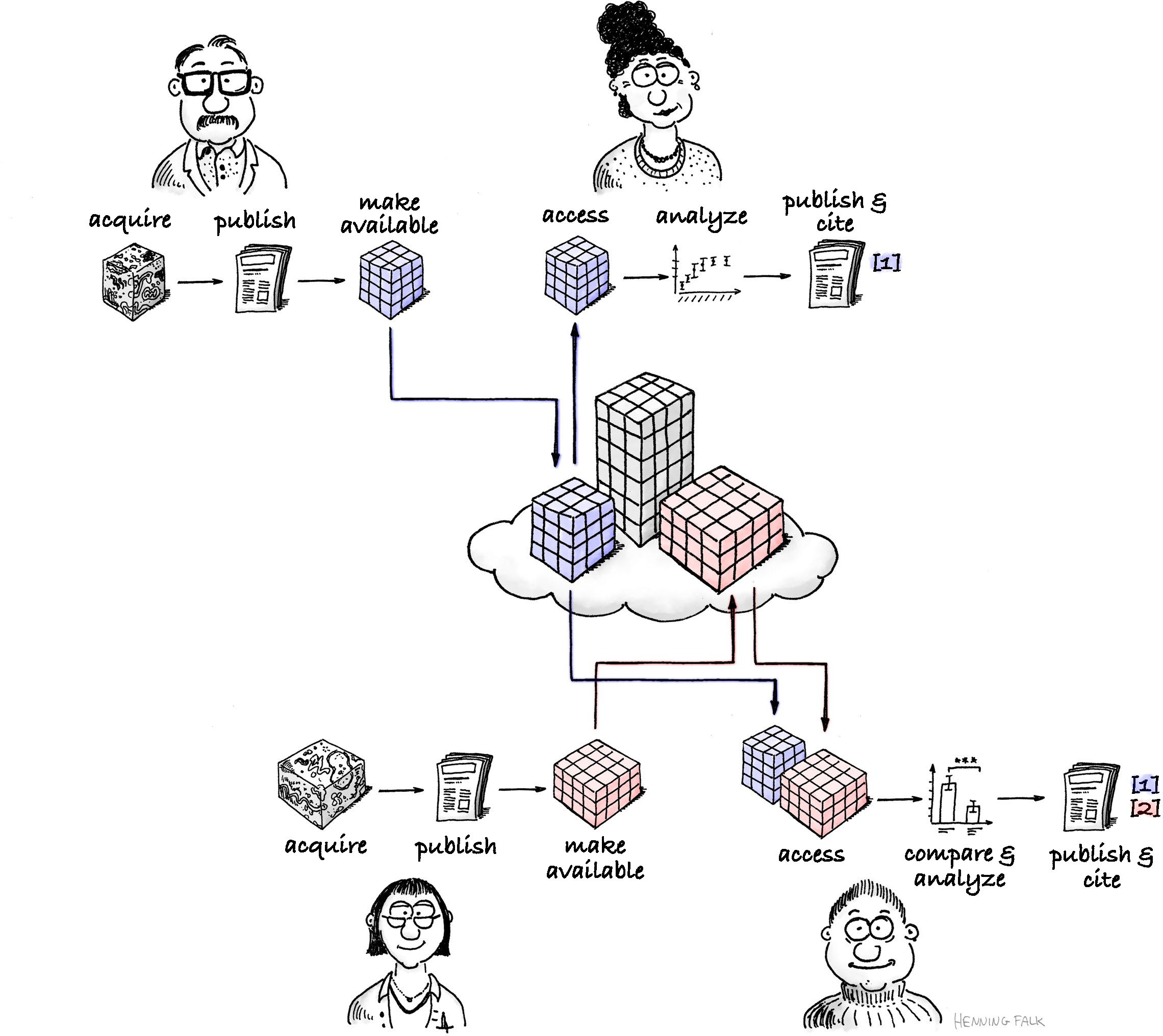
Figure 4:Ciclo de reuso y colaboración de datos FAIR. Imagen cortesía: Zarr illustrations
Los datos FAIR benefician a todos:
👩🔬 Productores de datos - Reciben citaciones cuando otros usan sus conjuntos de datos
👨💻 Consumidores de datos - Acceden a datos interesantes que de otro modo no estarían disponibles
🌍 La ciencia avanza - Mediante colaboración y el reuso de los datos
Formatos ARCO más comunes¶
Existen varios formatos diseñados para ser Analysis-Ready y Cloud-Optimized:
Zarr¶
Uso: Arrays N-dimensionales (datos climáticos, radar, satélite)
Ventajas: Fragmentación flexible, compresión, lectura paralela
Ecosistema: Xarray, Dask, Pangeo
Parquet¶
Uso: Datos tabulares (estaciones meteorológicas, series temporales)
Ventajas: Columnar, compresión eficiente
Ecosistema: Pandas, Dask, Apache Arrow
Cloud-Optimized GeoTIFF (COG)¶
Uso: Imágenes satelitales, rasters
Ventajas: Streaming eficiente, overview pyramids
Ecosistema: GDAL, Rasterio
En el siguiente cuadernillo nos enfocaremos en Zarr, el más usado para datos científicos multidimensionales.
Resumen¶
En este cuadernillo aprendiste los conceptos fundamentales de ARCO:
✅ Datos listos para análisis: Reducen el 80% del tiempo dedicado a limpieza de datos
✅ Formatos optimizados para la nube: Permiten acceso eficiente, paralelo y selectivo
✅ Principios FAIR: Hacen que los datos sean Encontrables, Accesibles, Interoperables y Reutilizables
✅ Fragmentación vs Monolítico: Los datos fragmentados permiten acceso selectivo
✅ Panorama de formatos: Zarr (arrays), Parquet (tabular), COG (rasters)
Estos conceptos son la base para trabajar con grandes volúmenes de datos científicos de manera eficiente en entornos modernos de computación.
¿Qué sigue?¶
Ahora que entiendes los conceptos ARCO, en el siguiente cuadernillo aprenderás Zarr en profundidad:
Qué es Zarr y cómo funciona
Exportar datos a formato Zarr
Usar carga perezosa (lazy loading)
Optimizar estrategias de fragmentación
Comparar rendimiento con formatos tradicionales
👉 Continúa con: Formato Zarr
📚 Recursos y Referencias¶
Abernathey, R. et al. (2021). Cloud-Native Repositories for Big Scientific Data. Computing in Science & Engineering, 23(2), 26-35.
Wilkinson, M. D. et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, 160018.
Crowdflower (2016). Data Science Report. https://
www2 .cs .uh .edu / ~ceick /UDM /CFDS16 .pdf Pangeo Community (2024). Cloud-Optimized Data Formats. https://pangeo.io/