Generating virutal datasets from GeoTiff files

Overview¶
In this tutorial we will cover:
How to generate virtual datasets from GeoTIFFs.
Combining virtual datasets.
Prerequisites¶
| Concepts | Importance | Notes |
|---|---|---|
| Basics of virtual Zarr stores | Required | Core |
| Multi-file virtual datasets with VirtualiZarr | Required | Core |
| Parallel virtual dataset creation with VirtualiZarr, Kerchunk, and Dask | Required | Core |
| Introduction to Xarray | Required | IO/Visualization |
Time to learn: 30 minutes
About the Dataset¶
The Finish Meterological Institute (FMI) Weather Radar Dataset is a collection of GeoTIFF files containing multiple radar specific variables, such as rainfall intensity, precipitation accumulation (in 1, 12 and 24 hour increments), radar reflectivity, radial velocity, rain classification and the cloud top height. It is available through the AWS public data portal and is updated frequently.
More details on this dataset can be found here.
import logging
from datetime import datetime
import dask
import fsspec
import rioxarray
import s3fs
import xarray as xr
from distributed import Client
from virtualizarr import open_virtual_datasetExamining a Single GeoTIFF File¶
Before we use Kerchunk to create indices for multiple files, we can load a single GeoTiff file to examine it.
# URL pointing to a single GeoTIFF file
url = "s3://fmi-opendata-radar-geotiff/2023/07/01/FIN-ACRR-3067-1KM/202307010100_FIN-ACRR1H-3067-1KM.tif"
# Initialize a s3 filesystem
fs = s3fs.S3FileSystem(anon=True)
xds = rioxarray.open_rasterio(fs.open(url))xdsxds.isel(band=0).where(xds < 2000).plot()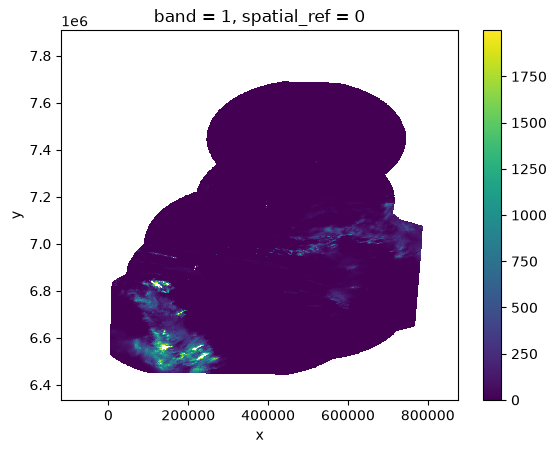
Create Input File List¶
Here we are using fsspec's glob functionality along with the * wildcard operator and some string slicing to grab a list of GeoTIFF files from a s3 fsspec filesystem.
# Initiate fsspec filesystems for reading
fs_read = fsspec.filesystem("s3", anon=True, skip_instance_cache=True)
files_paths = fs_read.glob(
"s3://fmi-opendata-radar-geotiff/2023/01/01/FIN-ACRR-3067-1KM/*24H-3067-1KM.tif"
)
# Here we prepend the prefix 's3://', which points to AWS.
files_paths = sorted(["s3://" + f for f in files_paths])Start a Dask Client¶
To parallelize the creation of our reference files, we will use Dask. For a detailed guide on how to use Dask and Kerchunk, see the Foundations notebook: Kerchunk and Dask.
client = Client(n_workers=8, silence_logs=logging.ERROR)
clientdef generate_virtual_dataset(file):
storage_options = dict(
anon=True, default_fill_cache=False, default_cache_type="none"
)
vds = open_virtual_dataset(
file,
indexes={},
filetype="tiff",
reader_options={
"remote_options": {"anon": True},
"storage_options": storage_options,
},
)
# Pre-process virtual datasets to extract time step information from the filename
subst = file.split("/")[-1].split(".json")[0].split("_")[0]
time_val = datetime.strptime(subst, "%Y%m%d%H%M")
vds = vds.expand_dims(dim={"time": [time_val]})
# Only include the raw data, not the overviews
vds = vds[["0"]]
return vds# Generate Dask Delayed objects
tasks = [dask.delayed(generate_virtual_dataset)(file) for file in files_paths]# Start parallel processing
import warnings
warnings.filterwarnings("ignore")
virtual_datasets = dask.compute(*tasks)2026-07-28 01:58:03,775 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-d5cf39b7-a6d6-4e3a-8c2e-5f89a5b2ae6f
State: executing
Task: <Task 'generate_virtual_dataset-d5cf39b7-a6d6-4e3a-8c2e-5f89a5b2ae6f' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:03,784 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-7055868f-3176-4e7e-b685-0e09eb0fd491
State: executing
Task: <Task 'generate_virtual_dataset-7055868f-3176-4e7e-b685-0e09eb0fd491' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:03,792 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-50d3687a-d0cf-4309-88d1-58be6759f353
State: executing
Task: <Task 'generate_virtual_dataset-50d3687a-d0cf-4309-88d1-58be6759f353' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:03,801 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-2acad4be-2d94-4277-bd49-af4091b1847f
State: executing
Task: <Task 'generate_virtual_dataset-2acad4be-2d94-4277-bd49-af4091b1847f' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:03,820 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-22714ee0-6054-47e4-9dff-91509e8ed79f
State: executing
Task: <Task 'generate_virtual_dataset-22714ee0-6054-47e4-9dff-91509e8ed79f' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:04,242 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-ddb71bbd-4f12-40ae-866c-2c2ac70b54da
State: executing
Task: <Task 'generate_virtual_dataset-ddb71bbd-4f12-40ae-866c-2c2ac70b54da' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[9], line 5
1 # Start parallel processing
2 import warnings
3
4 warnings.filterwarnings("ignore")
----> 5 virtual_datasets = dask.compute(*tasks)
File ~/micromamba/envs/kerchunk-cookbook/lib/python3.14/site-packages/dask/base.py:769, in compute(traverse, optimize_graph, scheduler, get, *args, **kwargs)
766 expr = expr.optimize()
767 keys = list(flatten(expr.__dask_keys__()))
--> 769 results = schedule(expr, keys, **kwargs)
771 return repack(results)
Cell In[7], line 5
----> 5 vds = open_virtual_dataset(
6 file,
7 indexes={},
8 filetype="tiff",
TypeError: open_virtual_dataset() got an unexpected keyword argument 'indexes'2026-07-28 01:58:04,480 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-cfa46aa7-8b88-4fdf-ab64-891060e8889d
State: executing
Task: <Task 'generate_virtual_dataset-cfa46aa7-8b88-4fdf-ab64-891060e8889d' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
2026-07-28 01:58:04,517 - distributed.worker - ERROR - Compute Failed
Key: generate_virtual_dataset-aaaf75f5-b21c-4b27-9159-70103b82959b
State: executing
Task: <Task 'generate_virtual_dataset-aaaf75f5-b21c-4b27-9159-70103b82959b' generate_virtual_dataset(...)>
Exception: 'TypeError("open_virtual_dataset() got an unexpected keyword argument \'indexes\'")'
Traceback: ' File "/tmp/ipykernel_5403/4131322973.py", line 5, in generate_virtual_dataset\n'
Combine virtual datasets¶
combined_vds = xr.concat(virtual_datasets, dim="time")
combined_vdsShut down the Dask cluster¶
client.shutdown()