Access ERA5 data from NCAR’s Research Data Archive and compute anomaly
Overview
ERA-5 Dataset is available from NCAR’s RDA in netcdf format as hourly files. A subset of this dataset is processed into Zarr format and available from NCAR RDA endpoints. To learn how you can create Zarr files from NCAR RDA netcdf files, please see this notebook.
In this notebook,
We will read data zarr stores from NCAR’s RDA endpoint
Compute temperature anomaly for the years 1940-2023
Prerequisites
Concepts |
Importance |
Notes |
|---|---|---|
Necessary |
||
Necessary |
||
Helpful |
Time to learn: 30 minutes
Imports
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
import intake_esm
import intake
import pandas as pd
import cartopy.crs as ccrs # Correct import for coordinate reference systems
import cartopy.feature as cfeature
from holoviews import opts
import geoviews as gv
import holoviews as hv
import aiohttp
/glade/u/apps/opt/conda/envs/npl-2024a/lib/python3.11/site-packages/dask/dataframe/_pyarrow_compat.py:17: FutureWarning: Minimal version of pyarrow will soon be increased to 14.0.1. You are using 13.0.0. Please consider upgrading.
warnings.warn(
Specify global variables
baseline_year_start = 1940
baseline_year_end = 1949
current_year = 2023
rda_data = '/gpfs/csfs1/collections/rda/data/'
rda_url = 'https://data.rda.ucar.edu/'
#era5_catalog = rda_url + 'pythia_intake_catalogs/era5_catalog.json'
#
annual_means = rda_url + 'pythia_era5_24/annual_means/'
annual_means_posix= rda_data + 'pythia_era5_24/annual_means/'
temp_annual_means = annual_means + ''
#
print(annual_means)
https://data.rda.ucar.edu/pythia_era5_24/annual_means/
Create a Dask cluster
Dask Introduction
Dask is a solution that enables the scaling of Python libraries. It mimics popular scientific libraries such as numpy, pandas, and xarray that enables an easier path to parallel processing without having to refactor code.
There are 3 components to parallel processing with Dask: the client, the scheduler, and the workers.
The Client is best envisioned as the application that sends information to the Dask cluster. In Python applications this is handled when the client is defined with client = Client(CLUSTER_TYPE). A Dask cluster comprises of a single scheduler that manages the execution of tasks on workers. The CLUSTER_TYPE can be defined in a number of different ways.
There is LocalCluster, a cluster running on the same hardware as the application and sharing the available resources, directly in Python with
dask.distributed.In certain JupyterHubs Dask Gateway may be available and a dedicated dask cluster with its own resources can be created dynamically with
dask.gateway.On HPC systems
dask_jobqueueis used to connect to the HPC Slurm and PBS job schedulers to provision resources.
The dask.distributed client python module can also be used to connect to existing clusters. A Dask Scheduler and Workers can be deployed in containers, or on Kubernetes, without using a Python function to create a dask cluster. The dask.distributed Client is configured to connect to the scheduler either by container name, or by the Kubernetes service name.
Select the Dask cluster type
The default will be LocalCluster as that can run on any system.
If running on a HPC computer with a PBS Scheduler, set to True. Otherwise, set to False.
USE_PBS_SCHEDULER = False
If running on Jupyter server with Dask Gateway configured, set to True. Otherwise, set to False.
USE_DASK_GATEWAY = False
Python function for a PBS Cluster
# Create a PBS cluster object
def get_pbs_cluster():
""" Create cluster through dask_jobqueue.
"""
from dask_jobqueue import PBSCluster
cluster = PBSCluster(
job_name = 'dask-pythia-24',
cores = 1,
memory = '4GiB',
processes = 1,
local_directory = rda_scratch + '/dask/spill',
resource_spec = 'select=1:ncpus=1:mem=4GB',
queue = 'casper',
walltime = '1:00:00',
#interface = 'ib0'
interface = 'ext'
)
return cluster
Python function for a Gateway Cluster
def get_gateway_cluster():
""" Create cluster through dask_gateway
"""
from dask_gateway import Gateway
gateway = Gateway()
cluster = gateway.new_cluster()
cluster.adapt(minimum=2, maximum=4)
return cluster
Python function for a Local Cluster
def get_local_cluster():
""" Create cluster using the Jupyter server's resources
"""
from distributed import LocalCluster, performance_report
cluster = LocalCluster()
cluster.scale(4)
return cluster
Python logic to select the Dask Cluster type
This uses True/False boolean logic based on the variables set in the previous cells
# Obtain dask cluster in one of three ways
if USE_PBS_SCHEDULER:
cluster = get_pbs_cluster()
elif USE_DASK_GATEWAY:
cluster = get_gateway_cluster()
else:
cluster = get_local_cluster()
# Connect to cluster
from distributed import Client
client = Client(cluster)
# Display cluster dashboard URL
cluster
/glade/u/apps/opt/conda/envs/npl-2024a/lib/python3.11/site-packages/distributed/node.py:182: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 43817 instead
warnings.warn(
Open ERA5 annual means file
baseline_temp = temp_2m_annual.sel(time= \
temp_2m_annual.time.dt.year.isin(range(baseline_year_start, baseline_year_end+1))).mean('time')
baseline_temp
<xarray.DataArray 'VAR_2T' (latitude: 721, longitude: 1440)> dask.array<mean_agg-aggregate, shape=(721, 1440), dtype=float32, chunksize=(721, 1440), chunktype=numpy.ndarray> Coordinates: * latitude (latitude) float64 90.0 89.75 89.5 89.25 ... -89.5 -89.75 -90.0 * longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.0 359.2 359.5 359.8
temp_anomaly = temp_2m_annual - baseline_temp
temp_anomaly
<xarray.DataArray 'VAR_2T' (time: 84, latitude: 721, longitude: 1440)> dask.array<sub, shape=(84, 721, 1440), dtype=float32, chunksize=(84, 721, 1440), chunktype=numpy.ndarray> Coordinates: * latitude (latitude) float64 90.0 89.75 89.5 89.25 ... -89.5 -89.75 -90.0 * longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.0 359.2 359.5 359.8 * time (time) datetime64[ns] 1940-12-31 1941-12-31 ... 2023-12-31
Save anomaly
# %%time
# temp_anomaly.to_dataset().to_zarr(annual_means_posix + 'temp_anomaly_wrt_1940_1950.zarr')
CPU times: user 337 ms, sys: 39.9 ms, total: 377 ms
Wall time: 5.29 s
<xarray.backends.zarr.ZarrStore at 0x148ae23d5cc0>
temp_anomaly = xr.open_zarr(annual_means_posix + 'temp_anomaly_wrt_1940_1950.zarr').VAR_2T
temp_anomaly
<xarray.DataArray 'VAR_2T' (time: 84, latitude: 721, longitude: 1440)> dask.array<open_dataset-VAR_2T, shape=(84, 721, 1440), dtype=float32, chunksize=(84, 721, 1440), chunktype=numpy.ndarray> Coordinates: * latitude (latitude) float64 90.0 89.75 89.5 89.25 ... -89.5 -89.75 -90.0 * longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.0 359.2 359.5 359.8 * time (time) datetime64[ns] 1940-12-31 1941-12-31 ... 2023-12-31
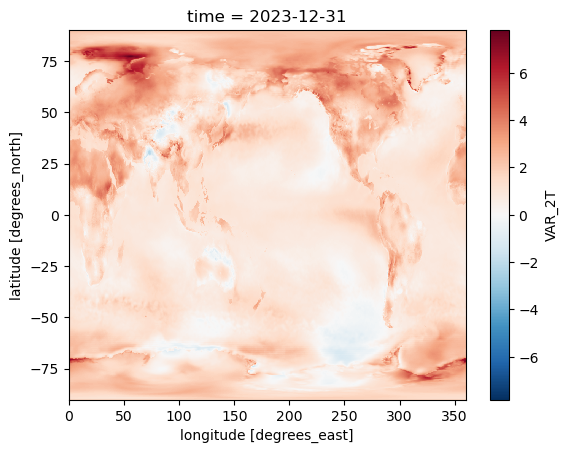
Plot the temperature anomaly
temp_anomaly.isel(time=83).plot()
<matplotlib.collections.QuadMesh at 0x148ae0d74990>
Close the Dask Cluster
It’s best practice to close the Dask cluster when it’s no longer needed to free up the compute resources used.
cluster.close()